
title stringlengths 12 150 | question_id int64 469 40.1M | question_score int64 2 5.52k | question_date stringdate 2008-08-02 15:11:16 2016-10-18 06:16:31 | answer_id int64 536 40.1M | answer_score int64 7 8.38k | answer_date stringdate 2008-08-02 18:49:07 2016-10-18 06:19:33 | tags listlengths 1 5 | question_body_md stringlengths 15 30.2k | answer_body_md stringlengths 11 27.8k |
|---|---|---|---|---|---|---|---|---|---|
How do I execute a program from python? os.system fails due to spaces in path | 204,017 | 206 | 2008-10-15T08:24:28Z | 911,976 | 26 | 2009-05-26T18:13:51Z | [
"python",
"shellexecute"
] | I have a python script that needs to execute an external program, but for some reason fails.
If I have the following script:
```
import os;
os.system("C:\\Temp\\a b c\\Notepad.exe");
raw_input();
```
Then it fails with the following error:
```
'C:\Temp\a' is not recognized as an internal or external command, operab... | The outermost quotes are consumed by Python itself, and the Windows shell doesn't see it. As mentioned above, Windows only understands double-quotes.
Python will convert forward-slashed to backslashes on Windows, so you can use
```
os.system('"C://Temp/a b c/Notepad.exe"')
```
The ' is consumed by Python, which then ... |
How do I execute a program from python? os.system fails due to spaces in path | 204,017 | 206 | 2008-10-15T08:24:28Z | 1,622,730 | 14 | 2009-10-26T01:33:47Z | [
"python",
"shellexecute"
] | I have a python script that needs to execute an external program, but for some reason fails.
If I have the following script:
```
import os;
os.system("C:\\Temp\\a b c\\Notepad.exe");
raw_input();
```
Then it fails with the following error:
```
'C:\Temp\a' is not recognized as an internal or external command, operab... | At least in Windows 7 and Python 3.1, os.system in Windows wants the command line *double-quoted* if there are spaces in path to the command. For example:
```
TheCommand = '\"\"C:\\Temp\\a b c\\Notepad.exe\"\"'
os.system(TheCommand)
```
A real-world example that was stumping me was cloning a drive in Virtual box.... |
Checking for member existence in Python | 204,308 | 23 | 2008-10-15T10:54:18Z | 204,481 | 10 | 2008-10-15T12:15:54Z | [
"python",
"exception",
"introspection",
"hasattr"
] | I regularly want to check if an object has a member or not. An example is the creation of a singleton in a function. For that purpose, you can use `hasattr` like this:
```
class Foo(object):
@classmethod
def singleton(self):
if not hasattr(self, 'instance'):
self.instance = Foo()
re... | I just tried to measure times:
```
class Foo(object):
@classmethod
def singleton(self):
if not hasattr(self, 'instance'):
self.instance = Foo()
return self.instance
class Bar(object):
@classmethod
def singleton(self):
try:
return self.instance
... |
Checking for member existence in Python | 204,308 | 23 | 2008-10-15T10:54:18Z | 204,523 | 21 | 2008-10-15T12:28:11Z | [
"python",
"exception",
"introspection",
"hasattr"
] | I regularly want to check if an object has a member or not. An example is the creation of a singleton in a function. For that purpose, you can use `hasattr` like this:
```
class Foo(object):
@classmethod
def singleton(self):
if not hasattr(self, 'instance'):
self.instance = Foo()
re... | These are two different methodologies: â1 is LBYL (look before you leap) and â2 is EAFP (easier to ask forgiveness than permission).
Pythonistas typically suggest that EAFP is better, with arguments in style of "what if a process creates the file between the time you test for it and the time you try to create it y... |
What would you recommend for a high traffic ajax intensive website? | 204,802 | 7 | 2008-10-15T13:57:23Z | 204,853 | 8 | 2008-10-15T14:11:29Z | [
"php",
"python",
"lighttpd",
"cherrypy",
"high-load"
] | For a website like reddit with lots of up/down votes and lots of comments per topic what should I go with?
Lighttpd/Php or Lighttpd/CherryPy/Genshi/SQLAlchemy?
and for database what would scale better / be fastest MySQL ( 4.1 or 5 ? ) or PostgreSQL? | I can't speak to the MySQL/PostgreSQL question as I have limited experience with Postgres, but my Masters research project was about high-performance websites with CherryPy, and I don't think you'll be disappointed if you use CherryPy for your site. It can easily scale to thousands of simultaneous users on commodity ha... |
What would you recommend for a high traffic ajax intensive website? | 204,802 | 7 | 2008-10-15T13:57:23Z | 204,916 | 8 | 2008-10-15T14:26:18Z | [
"php",
"python",
"lighttpd",
"cherrypy",
"high-load"
] | For a website like reddit with lots of up/down votes and lots of comments per topic what should I go with?
Lighttpd/Php or Lighttpd/CherryPy/Genshi/SQLAlchemy?
and for database what would scale better / be fastest MySQL ( 4.1 or 5 ? ) or PostgreSQL? | The ideal setup would be close to [this](http://www.igvita.com/2008/02/11/nginx-and-memcached-a-400-boost/):
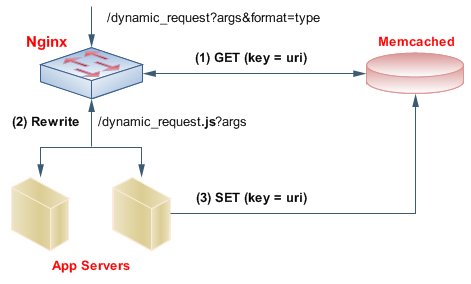
In short, [nginx](http://wiki.codemongers.com/) is a fast and light webserver/front-proxy with a unique module that let's it fetch data directl... |
Is it possible to compile Python natively (beyond pyc byte code)? | 205,062 | 13 | 2008-10-15T15:02:09Z | 205,075 | 7 | 2008-10-15T15:05:47Z | [
"python",
"module",
"compilation"
] | I wonder if it is possible to create an executable module from a Python script. I need to have the most performance and the flexibility of Python script, without needing to run in the Python environment. I would use this code to load on demand user modules to customize my application. | You can use something like py2exe to compile your python script into an exe, or Freeze for a linux binary.
see: <http://stackoverflow.com/questions/2933/an-executable-python-app#2937> |
Is it possible to compile Python natively (beyond pyc byte code)? | 205,062 | 13 | 2008-10-15T15:02:09Z | 205,096 | 14 | 2008-10-15T15:11:26Z | [
"python",
"module",
"compilation"
] | I wonder if it is possible to create an executable module from a Python script. I need to have the most performance and the flexibility of Python script, without needing to run in the Python environment. I would use this code to load on demand user modules to customize my application. | * There's [pyrex](http://www.cosc.canterbury.ac.nz/greg.ewing/python/Pyrex/) that compiles python like source to python extension modules
* [rpython](http://codespeak.net/pypy/dist/pypy/doc/coding-guide.html#our-runtime-interpreter-is-restricted-python) which allows you to compile python with some restrictions to vario... |
How can I check the syntax of Python code in Emacs without actually executing it? | 205,704 | 14 | 2008-10-15T17:46:12Z | 206,617 | 8 | 2008-10-15T21:40:49Z | [
"python",
"validation",
"emacs",
"syntax"
] | Python's IDLE has 'Check Module' (Alt-X) to check the syntax which can be called without needing to run the code. Is there an equivalent way to do this in Emacs instead of running and executing the code? | You can [use Pyflakes together with Flymake](http://www.plope.org/Members/chrism/flymake-mode) in order to get instant notification when your python code is valid (and avoids a few common pitfalls as well). |
How can I check the syntax of Python code in Emacs without actually executing it? | 205,704 | 14 | 2008-10-15T17:46:12Z | 8,584,325 | 17 | 2011-12-21T02:10:48Z | [
"python",
"validation",
"emacs",
"syntax"
] | Python's IDLE has 'Check Module' (Alt-X) to check the syntax which can be called without needing to run the code. Is there an equivalent way to do this in Emacs instead of running and executing the code? | ```
python -m py_compile script.py
``` |
Why do attribute references act like this with Python inheritance? | 206,734 | 16 | 2008-10-15T22:18:00Z | 206,765 | 22 | 2008-10-15T22:27:18Z | [
"python",
"class",
"inheritance"
] | The following seems strange.. Basically, the somedata attribute seems shared between all the classes that inherited from `the_base_class`.
```
class the_base_class:
somedata = {}
somedata['was_false_in_base'] = False
class subclassthing(the_base_class):
def __init__(self):
print self.somedata... | You are right, `somedata` is shared between all instances of the class and it's subclasses, because it is created at class *definition* time. The lines
```
somedata = {}
somedata['was_false_in_base'] = False
```
are executed when the class is defined, i.e. when the interpreter encounters the `class` statement - **not... |
Why do attribute references act like this with Python inheritance? | 206,734 | 16 | 2008-10-15T22:18:00Z | 206,800 | 10 | 2008-10-15T22:40:10Z | [
"python",
"class",
"inheritance"
] | The following seems strange.. Basically, the somedata attribute seems shared between all the classes that inherited from `the_base_class`.
```
class the_base_class:
somedata = {}
somedata['was_false_in_base'] = False
class subclassthing(the_base_class):
def __init__(self):
print self.somedata... | Note that part of the behavior youâre seeing is due to `somedata` being a `dict`, as opposed to a simple data type such as a `bool`.
For instance, see this different example which behaves differently (although very similar):
```
class the_base_class:
somedata = False
class subclassthing(the_base_class):
de... |
Scrape a dynamic website | 206,855 | 12 | 2008-10-15T23:04:13Z | 206,860 | 7 | 2008-10-15T23:09:14Z | [
"python",
"ajax",
"screen-scraping",
"beautifulsoup"
] | What is the best method to scrape a dynamic website where most of the content is generated by what appears to be ajax requests? I have previous experience with a Mechanize, BeautifulSoup, and python combo, but I am up for something new.
--Edit--
For more detail: I'm trying to scrape the CNN [primary database](http://w... | This is a difficult problem because you either have to reverse engineer the javascript on a per-site basis, or implement a javascript engine and run the scripts (which has its own difficulties and pitfalls).
It's a heavy weight solution, but I've seen people doing this with greasemonkey scripts - allow Firefox to rend... |
Scrape a dynamic website | 206,855 | 12 | 2008-10-15T23:04:13Z | 216,143 | 7 | 2008-10-19T07:38:59Z | [
"python",
"ajax",
"screen-scraping",
"beautifulsoup"
] | What is the best method to scrape a dynamic website where most of the content is generated by what appears to be ajax requests? I have previous experience with a Mechanize, BeautifulSoup, and python combo, but I am up for something new.
--Edit--
For more detail: I'm trying to scrape the CNN [primary database](http://w... | The best solution that I found was to use Firebug to monitor XmlHttpRequests, and then to use a script to resend them. |
Python: Difference between class and instance attributes | 207,000 | 84 | 2008-10-16T00:23:41Z | 207,128 | 100 | 2008-10-16T01:26:53Z | [
"python",
"attributes"
] | Is there any meaningful distinction between:
```
class A(object):
foo = 5 # some default value
```
vs.
```
class B(object):
def __init__(self, foo=5):
self.foo = foo
```
If you're creating a lot of instances, is there any difference in performance or space requirements for the two styles? When you... | Beyond performance considerations, there is a significant *semantic* difference. In the class attribute case, there is just one object referred to. In the instance-attribute-set-at-instantiation, there can be multiple objects referred to. For instance
```
>>> class A: foo = []
>>> a, b = A(), A()
>>> a.foo.append(5)
>... |
Python: Difference between class and instance attributes | 207,000 | 84 | 2008-10-16T00:23:41Z | 207,759 | 22 | 2008-10-16T08:16:28Z | [
"python",
"attributes"
] | Is there any meaningful distinction between:
```
class A(object):
foo = 5 # some default value
```
vs.
```
class B(object):
def __init__(self, foo=5):
self.foo = foo
```
If you're creating a lot of instances, is there any difference in performance or space requirements for the two styles? When you... | The difference is that the attribute on the class is shared by all instances. The attribute on an instance is unique to that instance.
If coming from C++, attributes on the class are more like static member variables. |
Python: Difference between class and instance attributes | 207,000 | 84 | 2008-10-16T00:23:41Z | 26,642,476 | 11 | 2014-10-29T23:32:51Z | [
"python",
"attributes"
] | Is there any meaningful distinction between:
```
class A(object):
foo = 5 # some default value
```
vs.
```
class B(object):
def __init__(self, foo=5):
self.foo = foo
```
If you're creating a lot of instances, is there any difference in performance or space requirements for the two styles? When you... | Since people in the comments here and in two other questions marked as dups all appear to be confused about this in the same way, I think it's worth adding an additional answer on top of [Alex Coventry's](http://stackoverflow.com/a/207128/908494).
The fact that Alex is assigning a value of a mutable type, like a list,... |
List of IP addresses/hostnames from local network in Python | 207,234 | 23 | 2008-10-16T02:32:33Z | 207,246 | 12 | 2008-10-16T02:38:02Z | [
"python",
"networking"
] | How can I get a list of the IP addresses or host names from a local network easily in Python?
It would be best if it was multi-platform, but it needs to work on Mac OS X first, then others follow.
**Edit:** By local I mean all **active** addresses within a local network, such as `192.168.xxx.xxx`.
So, if the IP addr... | If by "local" you mean on the same network segment, then you have to perform the following steps:
1. Determine your own IP address
2. Determine your own netmask
3. Determine the network range
4. Scan all the addresses (except the lowest, which is your network address and the highest, which is your broadcast address).
... |
List of IP addresses/hostnames from local network in Python | 207,234 | 23 | 2008-10-16T02:32:33Z | 602,965 | 14 | 2009-03-02T16:27:29Z | [
"python",
"networking"
] | How can I get a list of the IP addresses or host names from a local network easily in Python?
It would be best if it was multi-platform, but it needs to work on Mac OS X first, then others follow.
**Edit:** By local I mean all **active** addresses within a local network, such as `192.168.xxx.xxx`.
So, if the IP addr... | **Update**: The script is now located on [github](http://github.com/bwaldvogel/neighbourhood).
I wrote a [small python script](https://github.com/bwaldvogel/neighbourhood/blob/master/neighbourhood.py), that leverages [scapy](http://www.secdev.org/projects/scapy/)'s `arping()`. |
Python module that implements ftps | 207,939 | 9 | 2008-10-16T09:33:39Z | 208,256 | 9 | 2008-10-16T12:00:12Z | [
"python",
"ftps"
] | I was wondering if anybody could point me towards a free ftps module for python.
I am a complete newbie to python, but this is something I need for a work project. I need an ftps client to connect to a 3rd party ftps server.
thanks,
David. | I believe you could use Twisted to implement FTPS by simply using its FTP implementation, but changing the [`FTPClient.connectFactory`](http://twistedmatrix.com/trac/browser/trunk/twisted/protocols/ftp.py?rev=24609#L2186) attribute to be a function that does something with [`connectSSL`](http://twistedmatrix.com/docume... |
How to enable MySQL client auto re-connect with MySQLdb? | 207,981 | 30 | 2008-10-16T09:56:05Z | 210,096 | 7 | 2008-10-16T20:11:18Z | [
"python",
"mysql"
] | I came across PHP way of doing the trick:
```
my_bool reconnect = 1;
mysql_options(&mysql, MYSQL_OPT_RECONNECT, &reconnect);
```
but no luck with MySQLdb (python-mysql).
Can anybody please give a clue? Thanks. | If you are using ubuntu Linux there was a patch added to the python-mysql package that added the ability to set that same MYSQL\_OPT\_RECONNECT option (see [here](https://launchpad.net/ubuntu/hardy/+source/python-mysqldb/1.2.2-5)). I have not tried it though.
Unfortunately, the patch was later removed due to a conflic... |
How to enable MySQL client auto re-connect with MySQLdb? | 207,981 | 30 | 2008-10-16T09:56:05Z | 982,873 | 58 | 2009-06-11T18:38:11Z | [
"python",
"mysql"
] | I came across PHP way of doing the trick:
```
my_bool reconnect = 1;
mysql_options(&mysql, MYSQL_OPT_RECONNECT, &reconnect);
```
but no luck with MySQLdb (python-mysql).
Can anybody please give a clue? Thanks. | I solved this problem by creating a function that wraps the `cursor.execute()` method since that's what was throwing the `MySQLdb.OperationalError` exception. The other example above implies that it is the `conn.cursor()` method that throws this exception.
```
import MySQLdb
class DB:
conn = None
def connect(sel... |
How to enable MySQL client auto re-connect with MySQLdb? | 207,981 | 30 | 2008-10-16T09:56:05Z | 29,331,237 | 9 | 2015-03-29T15:48:28Z | [
"python",
"mysql"
] | I came across PHP way of doing the trick:
```
my_bool reconnect = 1;
mysql_options(&mysql, MYSQL_OPT_RECONNECT, &reconnect);
```
but no luck with MySQLdb (python-mysql).
Can anybody please give a clue? Thanks. | I had problems with the proposed solution because it didn't catch the exception. I am not sure why.
I have solved the problem with the `ping(True)` statement which I think is neater:
```
import MySQLdb
con=MySQLdb.Connect()
con.ping(True)
cur=con.cursor()
```
Got it from here: <http://www.neotitans.com/resources/pyt... |
How to read and write multiple files? | 208,120 | 4 | 2008-10-16T11:06:36Z | 208,156 | 9 | 2008-10-16T11:23:29Z | [
"python"
] | I want to write a program for this: In a folder I have *n* number of files; first read one file and perform some operation then store result in a separate file. Then read 2nd file, perform operation again and save result in new 2nd file. Do the same procedure for *n* number of files. The program reads all files one by ... | ```
import sys
# argv is your commandline arguments, argv[0] is your program name, so skip it
for n in sys.argv[1:]:
print(n) #print out the filename we are currently processing
input = open(n, "r")
output = open(n + ".out", "w")
# do some processing
input.close()
output.close()
```
Then call ... |
How to base64 encode a PDF file in Python | 208,894 | 6 | 2008-10-16T14:54:49Z | 210,534 | 21 | 2008-10-16T22:33:24Z | [
"python",
"encoding",
"base64",
"xml-rpc"
] | How should I base64 encode a PDF file for transport over XML-RPC in Python? | If you don't want to use the xmlrpclib's Binary class, you can just use the .encode() method of strings:
```
a = open("pdf_reference.pdf", "rb").read().encode("base64")
``` |
Can I use Python as a Bash replacement? | 209,470 | 207 | 2008-10-16T17:11:37Z | 209,557 | 8 | 2008-10-16T17:40:43Z | [
"python",
"bash",
"shell"
] | I currently do my textfile manipulation through a bunch of badly remembered AWK, sed, Bash and a tiny bit of Perl.
I've seen mentioned a few places that python is good for this kind of thing, I know a little and I would like to know more. Is Python a good choice for this, and is there a good book or guide to learning ... | I suggest the awesome online book *[Dive Into Python](http://www.diveintopython.net)*. It's how I learned the language originally.
Beyone teaching you the basic structure of the language, and a whole lot of useful data structures, it has a good chapter on [file handling](http://www.diveintopython.net/file_handling/ind... |
Can I use Python as a Bash replacement? | 209,470 | 207 | 2008-10-16T17:11:37Z | 209,562 | 127 | 2008-10-16T17:41:44Z | [
"python",
"bash",
"shell"
] | I currently do my textfile manipulation through a bunch of badly remembered AWK, sed, Bash and a tiny bit of Perl.
I've seen mentioned a few places that python is good for this kind of thing, I know a little and I would like to know more. Is Python a good choice for this, and is there a good book or guide to learning ... | Any shell has several sets of features.
* The Essential Linux/Unix commands. All of these are available through the [subprocess](https://docs.python.org/3/library/subprocess.html) library. This isn't always the best first choice for doing *all* external commands. Look also at [shutil](https://docs.python.org/3/library... |
Can I use Python as a Bash replacement? | 209,470 | 207 | 2008-10-16T17:11:37Z | 209,670 | 28 | 2008-10-16T18:16:52Z | [
"python",
"bash",
"shell"
] | I currently do my textfile manipulation through a bunch of badly remembered AWK, sed, Bash and a tiny bit of Perl.
I've seen mentioned a few places that python is good for this kind of thing, I know a little and I would like to know more. Is Python a good choice for this, and is there a good book or guide to learning ... | * If you want to use Python as a shell, why not have a look at [IPython](http://ipython.org/) ? It is also good to learn interactively the language.
* If you do a lot of text manipulation, and if you use Vim as a text editor, you can also directly write plugins for Vim in python. just type ":help python" in Vim and fol... |
Can I use Python as a Bash replacement? | 209,470 | 207 | 2008-10-16T17:11:37Z | 210,290 | 16 | 2008-10-16T20:58:33Z | [
"python",
"bash",
"shell"
] | I currently do my textfile manipulation through a bunch of badly remembered AWK, sed, Bash and a tiny bit of Perl.
I've seen mentioned a few places that python is good for this kind of thing, I know a little and I would like to know more. Is Python a good choice for this, and is there a good book or guide to learning ... | In the beginning there was sh, sed, and awk (and find, and grep, and...). It was good. But awk can be an odd little beast and hard to remember if you don't use it often. Then the great camel created Perl. Perl was a system administrator's dream. It was like shell scripting on steroids. Text processing, including regula... |
Can I use Python as a Bash replacement? | 209,470 | 207 | 2008-10-16T17:11:37Z | 12,915,952 | 81 | 2012-10-16T13:37:46Z | [
"python",
"bash",
"shell"
] | I currently do my textfile manipulation through a bunch of badly remembered AWK, sed, Bash and a tiny bit of Perl.
I've seen mentioned a few places that python is good for this kind of thing, I know a little and I would like to know more. Is Python a good choice for this, and is there a good book or guide to learning ... | Yes, of course :)
Take a look at these libraries which help you ***Never write shell scripts again*** (Plumbum's motto).
* [Plumbum](http://plumbum.readthedocs.org/en/latest/)
* [Sarge](https://bitbucket.org/vinay.sajip/sarge/)
* [sh](http://amoffat.github.com/sh/)
Also, if you want to replace awk, sed and grep with... |
Can I use Python as a Bash replacement? | 209,470 | 207 | 2008-10-16T17:11:37Z | 15,712,610 | 42 | 2013-03-29T22:49:18Z | [
"python",
"bash",
"shell"
] | I currently do my textfile manipulation through a bunch of badly remembered AWK, sed, Bash and a tiny bit of Perl.
I've seen mentioned a few places that python is good for this kind of thing, I know a little and I would like to know more. Is Python a good choice for this, and is there a good book or guide to learning ... | I just discovered how to combine the best parts of bash and ipython. Up to now this seems more comfortable to me than using subprocess and so on. You can easily copy big parts of existing bash scripts and e.g. add error handling in the python way :)
And here is my result:
```
#!/usr/bin/env ipython3
# *** How to have... |
Can I use Python as a Bash replacement? | 209,470 | 207 | 2008-10-16T17:11:37Z | 16,726,383 | 7 | 2013-05-24T01:23:24Z | [
"python",
"bash",
"shell"
] | I currently do my textfile manipulation through a bunch of badly remembered AWK, sed, Bash and a tiny bit of Perl.
I've seen mentioned a few places that python is good for this kind of thing, I know a little and I would like to know more. Is Python a good choice for this, and is there a good book or guide to learning ... | One reason I love Python is that it is much better standardized than the POSIX tools. I have to double and triple check that each bit is compatible with other operating systems. A program written on a Linux system might not work the same on a BSD system of OSX. With Python, I just have to check that the target system h... |
Can I use Python as a Bash replacement? | 209,470 | 207 | 2008-10-16T17:11:37Z | 30,617,053 | 33 | 2015-06-03T10:08:43Z | [
"python",
"bash",
"shell"
] | I currently do my textfile manipulation through a bunch of badly remembered AWK, sed, Bash and a tiny bit of Perl.
I've seen mentioned a few places that python is good for this kind of thing, I know a little and I would like to know more. Is Python a good choice for this, and is there a good book or guide to learning ... | As of 2015 and Python 3.4's release, there's now a reasonably complete user-interactive shell available at: <http://xon.sh/> or [https://github.com/scopatz/xonsh](https://github.com/scopatz/xonsh/)
The [demonstration video](http://xon.sh/_static/xonsh-demo.webm) does not show pipes being used, but they ARE supported w... |
Howto do python command-line autocompletion but NOT only at the beginning of a string | 209,484 | 6 | 2008-10-16T17:16:34Z | 209,503 | 10 | 2008-10-16T17:23:34Z | [
"python",
"linux",
"unix",
"command-line",
"autocomplete"
] | Python, through it's readline bindings allows for great command-line autocompletion (as described in [here](http://stackoverflow.com/questions/187621/how-to-make-a-python-command-line-program-autocomplete-arbitrary-things-not-int)).
But, the completion only seems to work at the beginning of strings. If you want to mat... | I'm not sure I understand the problem. You could use readline.clear\_history and readline.add\_history to set up the completable strings you want, then control-r to search backword in the history (just as if you were at a shell prompt). For example:
```
#!/usr/bin/env python
import readline
readline.clear_history()
... |
Convert hex string to int in Python | 209,513 | 414 | 2008-10-16T17:28:03Z | 209,529 | 99 | 2008-10-16T17:32:10Z | [
"python",
"string",
"hex"
] | How do I convert a hex string to an int in Python?
I may have it as "`0xffff`" or just "`ffff`". | `int(hexString, 16)` does the trick, and works with and without the 0x prefix:
```
>>> int("a", 16)
10
>>> int("0xa",16)
10
``` |
Convert hex string to int in Python | 209,513 | 414 | 2008-10-16T17:28:03Z | 209,530 | 32 | 2008-10-16T17:32:32Z | [
"python",
"string",
"hex"
] | How do I convert a hex string to an int in Python?
I may have it as "`0xffff`" or just "`ffff`". | For any given string s:
```
int(s, 16)
``` |
Convert hex string to int in Python | 209,513 | 414 | 2008-10-16T17:28:03Z | 209,550 | 594 | 2008-10-16T17:37:52Z | [
"python",
"string",
"hex"
] | How do I convert a hex string to an int in Python?
I may have it as "`0xffff`" or just "`ffff`". | **Without** the 0x prefix, you need to specify the base explicitly, otherwise there's no way to tell:
```
x = int("deadbeef", 16)
```
**With** the 0x prefix, Python can distinguish hex and decimal automatically.
```
>>> print int("0xdeadbeef", 0)
3735928559
>>> print int("10", 0)
10
```
(You *must* specify `0` as t... |
Convert hex string to int in Python | 209,513 | 414 | 2008-10-16T17:28:03Z | 11,275,700 | 9 | 2012-06-30T16:25:01Z | [
"python",
"string",
"hex"
] | How do I convert a hex string to an int in Python?
I may have it as "`0xffff`" or just "`ffff`". | Adding to Dan's answer above: if you supply the int() function with a hex string, you will have to specify the base as 16 or it will not think you gave it a valid value. Specifying base 16 is unnecessary for hex numbers not contained in strings.
```
print int(0xdeadbeef) # valid
myHex = "0xdeadbeef"
print int(myHex) ... |
Map two lists into a dictionary in Python | 209,840 | 435 | 2008-10-16T19:05:47Z | 209,854 | 770 | 2008-10-16T19:09:05Z | [
"python",
"dictionary"
] | Imagine that you have:
```
keys = ('name', 'age', 'food')
values = ('Monty', 42, 'spam')
```
What is the simplest way to produce the following dictionary ?
```
dict = {'name' : 'Monty', 'age' : 42, 'food' : 'spam'}
```
This code works, but I'm not really proud of it :
```
dict = {}
junk = map(lambda k, v: dict.upd... | Like this:
```
>>> keys = ['a', 'b', 'c']
>>> values = [1, 2, 3]
>>> dictionary = dict(zip(keys, values))
>>> print dictionary
{'a': 1, 'b': 2, 'c': 3}
```
Voila :-) The pairwise dict constructor and zip function are awesomely useful: <https://docs.python.org/2/library/functions.html#func-dict> |
Map two lists into a dictionary in Python | 209,840 | 435 | 2008-10-16T19:05:47Z | 209,855 | 25 | 2008-10-16T19:09:18Z | [
"python",
"dictionary"
] | Imagine that you have:
```
keys = ('name', 'age', 'food')
values = ('Monty', 42, 'spam')
```
What is the simplest way to produce the following dictionary ?
```
dict = {'name' : 'Monty', 'age' : 42, 'food' : 'spam'}
```
This code works, but I'm not really proud of it :
```
dict = {}
junk = map(lambda k, v: dict.upd... | ```
>>> keys = ('name', 'age', 'food')
>>> values = ('Monty', 42, 'spam')
>>> dict(zip(keys, values))
{'food': 'spam', 'age': 42, 'name': 'Monty'}
``` |
Map two lists into a dictionary in Python | 209,840 | 435 | 2008-10-16T19:05:47Z | 209,880 | 92 | 2008-10-16T19:16:02Z | [
"python",
"dictionary"
] | Imagine that you have:
```
keys = ('name', 'age', 'food')
values = ('Monty', 42, 'spam')
```
What is the simplest way to produce the following dictionary ?
```
dict = {'name' : 'Monty', 'age' : 42, 'food' : 'spam'}
```
This code works, but I'm not really proud of it :
```
dict = {}
junk = map(lambda k, v: dict.upd... | Try this:
```
>>> import itertools
>>> keys = ('name', 'age', 'food')
>>> values = ('Monty', 42, 'spam')
>>> adict = dict(itertools.izip(keys,values))
>>> adict
{'food': 'spam', 'age': 42, 'name': 'Monty'}
```
It was the simplest solution I could come up with.
PS It's also more economical in memory consumption compa... |
Map two lists into a dictionary in Python | 209,840 | 435 | 2008-10-16T19:05:47Z | 210,234 | 11 | 2008-10-16T20:45:04Z | [
"python",
"dictionary"
] | Imagine that you have:
```
keys = ('name', 'age', 'food')
values = ('Monty', 42, 'spam')
```
What is the simplest way to produce the following dictionary ?
```
dict = {'name' : 'Monty', 'age' : 42, 'food' : 'spam'}
```
This code works, but I'm not really proud of it :
```
dict = {}
junk = map(lambda k, v: dict.upd... | If you need to transform keys or values before creating a dictionary then a [generator expression](http://docs.python.org/ref/genexpr.html) could be used. Example:
```
>>> adict = dict((str(k), v) for k, v in zip(['a', 1, 'b'], [2, 'c', 3]))
```
Take a look [Code Like a Pythonista: Idiomatic Python](http://python.net... |
Map two lists into a dictionary in Python | 209,840 | 435 | 2008-10-16T19:05:47Z | 10,971,932 | 23 | 2012-06-10T20:03:34Z | [
"python",
"dictionary"
] | Imagine that you have:
```
keys = ('name', 'age', 'food')
values = ('Monty', 42, 'spam')
```
What is the simplest way to produce the following dictionary ?
```
dict = {'name' : 'Monty', 'age' : 42, 'food' : 'spam'}
```
This code works, but I'm not really proud of it :
```
dict = {}
junk = map(lambda k, v: dict.upd... | You can also use dictionary comprehensions in Python ⥠2.7:
```
>>> keys = ('name', 'age', 'food')
>>> values = ('Monty', 42, 'spam')
>>> {k: v for k, v in zip(keys, values)}
{'food': 'spam', 'age': 42, 'name': 'Monty'}
``` |
Map two lists into a dictionary in Python | 209,840 | 435 | 2008-10-16T19:05:47Z | 16,750,190 | 7 | 2013-05-25T13:47:03Z | [
"python",
"dictionary"
] | Imagine that you have:
```
keys = ('name', 'age', 'food')
values = ('Monty', 42, 'spam')
```
What is the simplest way to produce the following dictionary ?
```
dict = {'name' : 'Monty', 'age' : 42, 'food' : 'spam'}
```
This code works, but I'm not really proud of it :
```
dict = {}
junk = map(lambda k, v: dict.upd... | with Python 3.x, goes for dict comprehensions
```
keys = ('name', 'age', 'food')
values = ('Monty', 42, 'spam')
dic = {k:v for k,v in zip(keys, values)}
print(dic)
```
More on [dict comprehensions here](http://www.python.org/dev/peps/pep-0274/), an example is there:
```
>>> print {i : chr(65+i) for i in range(4)}
... |
Map two lists into a dictionary in Python | 209,840 | 435 | 2008-10-16T19:05:47Z | 33,737,067 | 21 | 2015-11-16T13:54:24Z | [
"python",
"dictionary"
] | Imagine that you have:
```
keys = ('name', 'age', 'food')
values = ('Monty', 42, 'spam')
```
What is the simplest way to produce the following dictionary ?
```
dict = {'name' : 'Monty', 'age' : 42, 'food' : 'spam'}
```
This code works, but I'm not really proud of it :
```
dict = {}
junk = map(lambda k, v: dict.upd... | > Imagine that you have:
>
> ```
> keys = ('name', 'age', 'food')
> values = ('Monty', 42, 'spam')
> ```
>
> **What is the simplest way to produce the following dictionary ?**
>
> ```
> dict = {'name' : 'Monty', 'age' : 42, 'food' : 'spam'}
> ```
# Python 2
I see some answers mentioning to use `izip` from `itertools`... |
Python: unsigned 32 bit bitwise arithmetic | 210,629 | 24 | 2008-10-16T23:25:31Z | 210,707 | 8 | 2008-10-17T00:04:03Z | [
"python",
"math"
] | Trying to answer to another post whose solution deals with IP addresses and netmasks, I got stuck with plain bitwise arithmetic.
Is there a standard way, in Python, to carry on bitwise AND, OR, XOR, NOT operations assuming that the inputs are "32 bit" (maybe negative) integers or longs, and that the result must be a l... | ```
from numpy import uint32
``` |
Python: unsigned 32 bit bitwise arithmetic | 210,629 | 24 | 2008-10-16T23:25:31Z | 210,740 | 47 | 2008-10-17T00:27:26Z | [
"python",
"math"
] | Trying to answer to another post whose solution deals with IP addresses and netmasks, I got stuck with plain bitwise arithmetic.
Is there a standard way, in Python, to carry on bitwise AND, OR, XOR, NOT operations assuming that the inputs are "32 bit" (maybe negative) integers or longs, and that the result must be a l... | You can use [ctypes](http://docs.python.org/lib/module-ctypes.html) and its `c_uint32`:
```
>>> import ctypes
>>> m = 0xFFFFFF00
>>> ctypes.c_uint32(~m).value
255L
```
So what I did here was casting `~m` to a C 32-bit unsigned integer and retrieving its value back in Python format. |
Python: unsigned 32 bit bitwise arithmetic | 210,629 | 24 | 2008-10-16T23:25:31Z | 210,747 | 32 | 2008-10-17T00:28:43Z | [
"python",
"math"
] | Trying to answer to another post whose solution deals with IP addresses and netmasks, I got stuck with plain bitwise arithmetic.
Is there a standard way, in Python, to carry on bitwise AND, OR, XOR, NOT operations assuming that the inputs are "32 bit" (maybe negative) integers or longs, and that the result must be a l... | You can mask everything by `0xFFFFFFFF`:
```
>>> m = 0xFFFFFF00
>>> allf = 0xFFFFFFFF
>>> ~m & allf
255L
``` |
Using os.execvp in Python | 210,978 | 6 | 2008-10-17T03:04:38Z | 210,982 | 11 | 2008-10-17T03:07:53Z | [
"python",
"shell",
"exec"
] | I have a question about using `os.execvp` in Python. I have the following bit of code that's used to create a list of arguments:
```
args = [ "java"
, classpath
, "-Djava.library.path=" + lib_path()
, ea
, "-Xmx1000m"
, "-server"
, "code_swarm"
, params
]
```
Wh... | If your "classpath" variable contains for instance "-classpath foo.jar", it will not work, since it is thinking the option name is "-classpath foo.jar". Split it in two arguments: [..., "-classpath", classpath, ...].
The other ways (copy and paste and system()) work because the shell splits the command line at the spa... |
Python's __import__ doesn't work as expected | 211,100 | 40 | 2008-10-17T04:46:08Z | 211,101 | 51 | 2008-10-17T04:46:20Z | [
"python",
"python-import"
] | When using `__import__` with a dotted name, something like: `somepackage.somemodule`, the module returned isn't `somemodule`, whatever is returned seems to be mostly empty! what's going on here? | From the python docs on `__import__`:
> ```
> __import__( name[, globals[, locals[, fromlist[, level]]]])
> ```
>
> ...
>
> When the name variable is of the form
> package.module, normally, the
> top-level package (the name up till
> the first dot) is returned, not the
> module named by name. However, when a
> non-emp... |
Python's __import__ doesn't work as expected | 211,100 | 40 | 2008-10-17T04:46:08Z | 214,682 | 7 | 2008-10-18T06:37:19Z | [
"python",
"python-import"
] | When using `__import__` with a dotted name, something like: `somepackage.somemodule`, the module returned isn't `somemodule`, whatever is returned seems to be mostly empty! what's going on here? | There is something that works as you want it to: `twisted.python.reflect.namedAny`:
```
>>> from twisted.python.reflect import namedAny
>>> namedAny("operator.eq")
<built-in function eq>
>>> namedAny("pysqlite2.dbapi2.connect")
<built-in function connect>
>>> namedAny("os")
<module 'os' from '/usr/lib/python2.5/os.pyc... |
Python's __import__ doesn't work as expected | 211,100 | 40 | 2008-10-17T04:46:08Z | 5,138,775 | 32 | 2011-02-28T06:08:46Z | [
"python",
"python-import"
] | When using `__import__` with a dotted name, something like: `somepackage.somemodule`, the module returned isn't `somemodule`, whatever is returned seems to be mostly empty! what's going on here? | python 2.7 has importlib, dotted paths resolve as expected
```
import importlib
foo = importlib.import_module('a.dotted.path')
instance = foo.SomeClass()
``` |
Python's __import__ doesn't work as expected | 211,100 | 40 | 2008-10-17T04:46:08Z | 6,957,437 | 16 | 2011-08-05T13:54:49Z | [
"python",
"python-import"
] | When using `__import__` with a dotted name, something like: `somepackage.somemodule`, the module returned isn't `somemodule`, whatever is returned seems to be mostly empty! what's going on here? | There is a simpler solution, as explained in the documentation:
If you simply want to import a module (potentially within a package) by name, you can call \_\_import\_\_() and then look it up in sys.modules:
```
>>> import sys
>>> name = 'foo.bar.baz'
>>> __import__(name)
<module 'foo' from ...>
>>> baz = sys.modules... |
How to build "Tagging" support using CouchDB? | 211,118 | 4 | 2008-10-17T04:57:22Z | 213,138 | 7 | 2008-10-17T17:48:37Z | [
"python",
"couchdb",
"tagging",
"document-oriented-db"
] | I'm using the following view function to iterate over all items in the database (in order to find a tag), but I think the performance is very poor if the dataset is large.
Any other approach?
```
def by_tag(tag):
return '''
function(doc) {
if (doc.tags.length > 0) {
for (var tag in... | *Disclaimer: I didn't test this and don't know if it can perform better.*
Create a single perm view:
```
function(doc) {
for (var tag in doc.tags) {
emit([tag, doc.published], doc)
}
};
```
And query with
\_view/your\_view/all?startkey=['your\_tag\_here']&endkey=['your\_tag\_here', {}]
Resulting JSON struct... |
Python Inverse of a Matrix | 211,160 | 50 | 2008-10-17T05:30:49Z | 211,174 | 93 | 2008-10-17T05:41:42Z | [
"python",
"algorithm",
"matrix",
"linear-algebra",
"matrix-inverse"
] | How do I get the inverse of a matrix in python? I've implemented it myself, but it's pure python, and I suspect there are faster modules out there to do it. | You should have a look at [numpy](http://www.scipy.org/Tentative_NumPy_Tutorial) if you do matrix manipulation. This is a module mainly written in C, which will be much faster than programming in pure python. Here is an example of how to invert a matrix, and do other matrix manipulation.
```
from numpy import matrix
f... |
Python Inverse of a Matrix | 211,160 | 50 | 2008-10-17T05:30:49Z | 215,523 | 44 | 2008-10-18T20:12:27Z | [
"python",
"algorithm",
"matrix",
"linear-algebra",
"matrix-inverse"
] | How do I get the inverse of a matrix in python? I've implemented it myself, but it's pure python, and I suspect there are faster modules out there to do it. | Make sure you really need to invert the matrix. This is often unnecessary and can be numerically unstable. When most people ask how to invert a matrix, they really want to know how to solve Ax = b where A is a matrix and x and b are vectors. It's more efficient and more accurate to use code that solves the equation Ax ... |
Python Inverse of a Matrix | 211,160 | 50 | 2008-10-17T05:30:49Z | 3,128,931 | 9 | 2010-06-27T21:19:14Z | [
"python",
"algorithm",
"matrix",
"linear-algebra",
"matrix-inverse"
] | How do I get the inverse of a matrix in python? I've implemented it myself, but it's pure python, and I suspect there are faster modules out there to do it. | It is a pity that the chosen matrix, repeated here again, is either singular or badly conditioned:
```
A = matrix( [[1,2,3],[11,12,13],[21,22,23]])
```
By definition, the inverse of A when multiplied by the matrix A itself must give a unit matrix. The A chosen in the much praised explanation does not do that. In fact... |
Using SQLite in a Python program | 211,501 | 13 | 2008-10-17T09:02:12Z | 211,534 | 12 | 2008-10-17T09:23:01Z | [
"python",
"exception",
"sqlite"
] | I have created a Python module that creates and populates several SQLite tables. Now, I want to use it in a program but I don't really know how to call it properly. All the tutorials I've found are essentially "inline", i.e. they walk through using SQLite in a linear fashion rather than how to actually use it in produc... | AFAIK an SQLITE database is just a file.
To check if the database exists, check for file existence.
When you open a SQLITE database it will automatically create one if the file that backs it up is not in place.
If you try and open a file as a sqlite3 database that is NOT a database, you will get this:
"sqlite3.Datab... |
Using SQLite in a Python program | 211,501 | 13 | 2008-10-17T09:02:12Z | 211,573 | 7 | 2008-10-17T09:44:53Z | [
"python",
"exception",
"sqlite"
] | I have created a Python module that creates and populates several SQLite tables. Now, I want to use it in a program but I don't really know how to call it properly. All the tutorials I've found are essentially "inline", i.e. they walk through using SQLite in a linear fashion rather than how to actually use it in produc... | SQLite automatically creates the database file the first time you try to use it. The SQL statements for creating tables can use `IF NOT EXISTS` to make the commands only take effect if the table has not been created This way you don't need to check for the database's existence beforehand: SQLite can take care of that f... |
Using SQLite in a Python program | 211,501 | 13 | 2008-10-17T09:02:12Z | 211,660 | 28 | 2008-10-17T10:30:02Z | [
"python",
"exception",
"sqlite"
] | I have created a Python module that creates and populates several SQLite tables. Now, I want to use it in a program but I don't really know how to call it properly. All the tutorials I've found are essentially "inline", i.e. they walk through using SQLite in a linear fashion rather than how to actually use it in produc... | Don't make this more complex than it needs to be. The big, independent databases have complex setup and configuration requirements. SQLite is just a file you access with SQL, it's much simpler.
Do the following.
1. Add a table to your database for "Components" or "Versions" or "Configuration" or "Release" or somethin... |
What is an easy way to create a trivial one-off Python object? | 211,695 | 9 | 2008-10-17T10:47:49Z | 211,774 | 14 | 2008-10-17T11:17:06Z | [
"python"
] | I would like to create a trivial one-off Python object to hold some command-line options. I would like to do something like this:
```
options = ??????
options.VERBOSE = True
options.IGNORE_WARNINGS = False
# Then, elsewhere in the code...
if options.VERBOSE:
...
```
Of course I could use a dictionary, but `optio... | The [collections module](http://docs.python.org/library/collections.html) has grown a *namedtuple* function in 2.6:
```
import collections
opt=collections.namedtuple('options','VERBOSE IGNORE_WARNINGS')
myoptions=opt(True, False)
>>> myoptions
options(VERBOSE=True, IGNORE_WARNINGS=False)
>>> myoptions.VERBOSE
True
``... |
What is an easy way to create a trivial one-off Python object? | 211,695 | 9 | 2008-10-17T10:47:49Z | 212,299 | 8 | 2008-10-17T14:10:03Z | [
"python"
] | I would like to create a trivial one-off Python object to hold some command-line options. I would like to do something like this:
```
options = ??????
options.VERBOSE = True
options.IGNORE_WARNINGS = False
# Then, elsewhere in the code...
if options.VERBOSE:
...
```
Of course I could use a dictionary, but `optio... | Given your requirements, I'd say the custom class is your best bet:
```
class options(object):
VERBOSE = True
IGNORE_WARNINGS = True
if options.VERBOSE:
# ...
```
To be complete, another approach would be using a separate module, i.e. `options.py` to encapsulate your option defaults.
`options.py`:
```
... |
What is an easy way to create a trivial one-off Python object? | 211,695 | 9 | 2008-10-17T10:47:49Z | 212,959 | 7 | 2008-10-17T16:56:19Z | [
"python"
] | I would like to create a trivial one-off Python object to hold some command-line options. I would like to do something like this:
```
options = ??????
options.VERBOSE = True
options.IGNORE_WARNINGS = False
# Then, elsewhere in the code...
if options.VERBOSE:
...
```
Of course I could use a dictionary, but `optio... | Why not just use [optparse](http://docs.python.org/library/optparse.html#module-optparse):
```
from optparse import OptionParser
[...]
parser = OptionParser()
parser.add_option("-f", "--file", dest="filename",
help="write report to FILE", metavar="FILE")
parser.add_option("-q", "--quiet",
a... |
Binary search (bisection) in Python | 212,358 | 129 | 2008-10-17T14:23:17Z | 212,413 | 51 | 2008-10-17T14:36:49Z | [
"python",
"binary-search",
"bisection"
] | Is there a library function that performs binary search on a list/tuple and return the position of the item if found and 'False' (-1, None, etc.) if not?
I found the functions bisect\_left/right in the [bisect module](http://docs.python.org/library/bisect.html), but they still return a position even if the item is not... | Why not look at the code for bisect\_left/right and adapt it to suit your purpose.
like this:
```
def binary_search(a, x, lo=0, hi=None):
if hi is None:
hi = len(a)
while lo < hi:
mid = (lo+hi)//2
midval = a[mid]
if midval < x:
lo = mid+1
elif midval > x:
... |
Binary search (bisection) in Python | 212,358 | 129 | 2008-10-17T14:23:17Z | 212,971 | 32 | 2008-10-17T16:59:57Z | [
"python",
"binary-search",
"bisection"
] | Is there a library function that performs binary search on a list/tuple and return the position of the item if found and 'False' (-1, None, etc.) if not?
I found the functions bisect\_left/right in the [bisect module](http://docs.python.org/library/bisect.html), but they still return a position even if the item is not... | This is a little off-topic (since Moe's answer seems complete to the OP's question), but it might be worth looking at the complexity for your whole procedure from end to end. If you're storing thing in a sorted lists (which is where a binary search would help), and then just checking for existence, you're incurring (wo... |
Binary search (bisection) in Python | 212,358 | 129 | 2008-10-17T14:23:17Z | 530,397 | 10 | 2009-02-09T22:41:14Z | [
"python",
"binary-search",
"bisection"
] | Is there a library function that performs binary search on a list/tuple and return the position of the item if found and 'False' (-1, None, etc.) if not?
I found the functions bisect\_left/right in the [bisect module](http://docs.python.org/library/bisect.html), but they still return a position even if the item is not... | Simplest is to use [bisect](http://docs.python.org/library/bisect.html) and check one position back to see if the item is there:
```
def binary_search(a,x,lo=0,hi=-1):
i = bisect(a,x,lo,hi)
if i == 0:
return -1
elif a[i-1] == x:
return i-1
else:
return -1
``` |
Binary search (bisection) in Python | 212,358 | 129 | 2008-10-17T14:23:17Z | 2,233,940 | 170 | 2010-02-10T02:05:27Z | [
"python",
"binary-search",
"bisection"
] | Is there a library function that performs binary search on a list/tuple and return the position of the item if found and 'False' (-1, None, etc.) if not?
I found the functions bisect\_left/right in the [bisect module](http://docs.python.org/library/bisect.html), but they still return a position even if the item is not... | ```
from bisect import bisect_left
def binary_search(a, x, lo=0, hi=None): # can't use a to specify default for hi
hi = hi if hi is not None else len(a) # hi defaults to len(a)
pos = bisect_left(a,x,lo,hi) # find insertion position
return (pos if pos != hi and a[pos] == x else -1) # don't wal... |
Binary search (bisection) in Python | 212,358 | 129 | 2008-10-17T14:23:17Z | 5,763,198 | 10 | 2011-04-23T08:36:45Z | [
"python",
"binary-search",
"bisection"
] | Is there a library function that performs binary search on a list/tuple and return the position of the item if found and 'False' (-1, None, etc.) if not?
I found the functions bisect\_left/right in the [bisect module](http://docs.python.org/library/bisect.html), but they still return a position even if the item is not... | It might be worth mentioning that the bisect docs now provide searching examples:
<http://docs.python.org/library/bisect.html#searching-sorted-lists>
(Raising ValueError instead of returning -1 or None is more pythonic â list.index() does it, for example. But of course you can adapt the examples to your needs.) |
Using django-rest-interface | 212,941 | 20 | 2008-10-17T16:53:23Z | 996,423 | 12 | 2009-06-15T14:28:37Z | [
"python",
"django",
"rest"
] | I have a django application that I'd like to add some rest interfaces to. I've seen <http://code.google.com/p/django-rest-interface/> but it seems to be pretty simplistic. For instance it doesn't seem to have a way of enforcing security. How would I go about limiting what people can view and manipulate through the rest... | I would look into using django-piston <http://bitbucket.org/jespern/django-piston/wiki/Home> application if security is your main concern.
I have used django-rest-interface in the past, its reliable and though simple can be quite powerful, however django-piston seems more flexible going forward. |
python threadsafe object cache | 213,455 | 9 | 2008-10-17T19:05:20Z | 213,768 | 8 | 2008-10-17T20:39:48Z | [
"python",
"multithreading",
"caching"
] | I have implemented a python webserver. Each http request spawns a new thread.
I have a requirement of caching objects in memory and since its a webserver, I want the cache to be thread safe. Is there a standard implementatin of a thread safe object cache in python? I found the following
<http://freshmeat.net/projects/... | Thread per request is often a bad idea. If your server experiences huge spikes in load it will take the box to its knees. Consider using a thread pool that can grow to a limited size during peak usage and shrink to a smaller size when load is light. |
python threadsafe object cache | 213,455 | 9 | 2008-10-17T19:05:20Z | 215,329 | 7 | 2008-10-18T17:48:05Z | [
"python",
"multithreading",
"caching"
] | I have implemented a python webserver. Each http request spawns a new thread.
I have a requirement of caching objects in memory and since its a webserver, I want the cache to be thread safe. Is there a standard implementatin of a thread safe object cache in python? I found the following
<http://freshmeat.net/projects/... | Well a lot of operations in Python are thread-safe by default, so a standard dictionary should be ok (at least in certain respects). This is mostly due to the GIL, which will help avoid some of the more serious threading issues.
There's a list here: <http://coreygoldberg.blogspot.com/2008/09/python-thread-synchronizat... |
A good multithreaded python webserver? | 213,483 | 13 | 2008-10-17T19:12:38Z | 213,563 | 16 | 2008-10-17T19:33:25Z | [
"python",
"apache",
"webserver",
"mod-python"
] | I am looking for a python webserver which is multithreaded instead of being multi-process (as in case of mod\_python for apache). I want it to be multithreaded because I want to have an in memory object cache that will be used by various http threads. My webserver does a lot of expensive stuff and computes some large a... | [CherryPy](http://cherrypy.org/). Features, as listed from the website:
* A fast, HTTP/1.1-compliant, WSGI thread-pooled webserver. Typically, CherryPy itself takes only 1-2ms per page!
* Support for any other WSGI-enabled webserver or adapter, including Apache, IIS, lighttpd, mod\_python, FastCGI, SCGI, and mod\_wsgi... |
A good multithreaded python webserver? | 213,483 | 13 | 2008-10-17T19:12:38Z | 213,572 | 7 | 2008-10-17T19:35:04Z | [
"python",
"apache",
"webserver",
"mod-python"
] | I am looking for a python webserver which is multithreaded instead of being multi-process (as in case of mod\_python for apache). I want it to be multithreaded because I want to have an in memory object cache that will be used by various http threads. My webserver does a lot of expensive stuff and computes some large a... | Consider reconsidering your design. Maintaining that much state in your webserver is probably a bad idea. Multi-process is a much better way to go for stability.
Is there another way to share state between separate processes? What about a service? Database? Index?
It seems unlikely that maintaining a huge array of da... |
Would Python make a good substitute for the Windows command-line/batch scripts? | 213,798 | 20 | 2008-10-17T20:48:26Z | 213,810 | 17 | 2008-10-17T20:50:57Z | [
"python",
"command-line",
"scripting"
] | I've got some experience with [Bash](http://en.wikipedia.org/wiki/Bash_%28Unix_shell%29), which I don't mind, but now that I'm doing a lot of Windows development I'm needing to do basic stuff/write basic scripts using
the Windows command-line language. For some reason said language really irritates me, so I was conside... | Python is well suited for these tasks, and I would guess much easier to develop in and debug than Windows batch files.
The question is, I think, how easy and painless it is to ensure that all the computers that you have to run these scripts on, have Python installed. |
Would Python make a good substitute for the Windows command-line/batch scripts? | 213,798 | 20 | 2008-10-17T20:48:26Z | 213,820 | 7 | 2008-10-17T20:54:39Z | [
"python",
"command-line",
"scripting"
] | I've got some experience with [Bash](http://en.wikipedia.org/wiki/Bash_%28Unix_shell%29), which I don't mind, but now that I'm doing a lot of Windows development I'm needing to do basic stuff/write basic scripts using
the Windows command-line language. For some reason said language really irritates me, so I was conside... | Sure, python is a pretty good choice for those tasks (I'm sure many will recommend PowerShell instead).
Here is a fine introduction from that point of view:
<http://www.redhatmagazine.com/2008/02/07/python-for-bash-scripters-a-well-kept-secret/>
EDIT: About gnud's concern: <http://www.portablepython.com/> |
Would Python make a good substitute for the Windows command-line/batch scripts? | 213,798 | 20 | 2008-10-17T20:48:26Z | 216,285 | 9 | 2008-10-19T11:14:49Z | [
"python",
"command-line",
"scripting"
] | I've got some experience with [Bash](http://en.wikipedia.org/wiki/Bash_%28Unix_shell%29), which I don't mind, but now that I'm doing a lot of Windows development I'm needing to do basic stuff/write basic scripts using
the Windows command-line language. For some reason said language really irritates me, so I was conside... | ## Summary
**Windows**: no need to think, use Python.
**Unix**: quick or run-it-once scripts are for Bash, serious and/or long life time scripts are for Python.
## The big talk
In a Windows environment, Python is definitely the best choice since [cmd](http://en.wikipedia.org/wiki/Command_Prompt) is crappy and PowerS... |
How to create a numpy record array from C | 214,549 | 7 | 2008-10-18T04:03:35Z | 215,090 | 8 | 2008-10-18T14:19:14Z | [
"python",
"c",
"numpy"
] | On the Python side, I can create new numpy record arrays as follows:
```
numpy.zeros((3,), dtype=[('a', 'i4'), ('b', 'U5')])
```
How do I do the same from a C program? I suppose I have to call `PyArray_SimpleNewFromDescr(nd, dims, descr)`, but how do I construct a `PyArray_Descr` that is appropriate for passing as th... | Use `PyArray_DescrConverter`. Here's an example:
```
#include <Python.h>
#include <stdio.h>
#include <numpy/arrayobject.h>
int main(int argc, char *argv[])
{
int dims[] = { 2, 3 };
PyObject *op, *array;
PyArray_Descr *descr;
Py_Initialize();
import_array();
op = Py_BuildValue("[(s, s), ... |
How do you convert YYYY-MM-DDTHH:mm:ss.000Z time format to MM/DD/YYYY time format in Python? | 214,777 | 18 | 2008-10-18T08:53:02Z | 214,786 | 14 | 2008-10-18T09:01:59Z | [
"python",
"datetime"
] | For example, I'm trying to convert 2008-09-26T01:51:42.000Z to 09/26/2008. What's the simplest way of accomplishing this? | ```
>>> import time
>>> timestamp = "2008-09-26T01:51:42.000Z"
>>> ts = time.strptime(timestamp[:19], "%Y-%m-%dT%H:%M:%S")
>>> time.strftime("%m/%d/%Y", ts)
'09/26/2008'
```
See the documentation of the Python [`time`](http://python.org/doc/2.5/lib/module-time.html) module for more information. |
How do you convert YYYY-MM-DDTHH:mm:ss.000Z time format to MM/DD/YYYY time format in Python? | 214,777 | 18 | 2008-10-18T08:53:02Z | 215,313 | 24 | 2008-10-18T17:33:30Z | [
"python",
"datetime"
] | For example, I'm trying to convert 2008-09-26T01:51:42.000Z to 09/26/2008. What's the simplest way of accomplishing this? | The easiest way is to use [dateutil](http://labix.org/python-dateutil).parser.parse() to parse the date string into a timezone aware datetime object, then use strftime() to get the format you want.
```
import datetime, dateutil.parser
d = dateutil.parser.parse('2008-09-26T01:51:42.000Z')
print d.strftime('%m/%d/%Y') ... |
python module dlls | 214,852 | 11 | 2008-10-18T10:17:58Z | 214,868 | 14 | 2008-10-18T10:33:08Z | [
"python",
"module"
] | Is there a way to make a python module load a dll in my application directory rather than the version that came with the python installation, without making changes to the python installation (which would then require I made an installer, and be careful I didn't break other apps for people by overwrting python modules ... | If you're talking about Python module DLLs, then simply modifying `sys.path` should be fine. However, if you're talking about DLLs *linked* against those DLLs; i.e. a `libfoo.dll` which a `foo.pyd` depends on, then you need to modify your PATH environment variable. I wrote about [doing this for PyGTK a while ago](http:... |
Can you add new statements to Python's syntax? | 214,881 | 72 | 2008-10-18T10:47:21Z | 214,910 | 12 | 2008-10-18T11:16:45Z | [
"python",
"syntax"
] | Can you add new statements (like `print`, `raise`, `with`) to Python's syntax?
Say, to allow..
```
mystatement "Something"
```
Or,
```
new_if True:
print "example"
```
Not so much if you *should*, but rather if it's possible (short of modifying the python interpreters code) | Short of changing and recompiling the source code (which *is* possible with open source), changing the base language is not really possible.
Even if you do recompile the source, it wouldn't be python, just your hacked-up changed version which you need to be very careful not to introduce bugs into.
However, I'm not su... |
Can you add new statements to Python's syntax? | 214,881 | 72 | 2008-10-18T10:47:21Z | 215,697 | 44 | 2008-10-18T23:15:04Z | [
"python",
"syntax"
] | Can you add new statements (like `print`, `raise`, `with`) to Python's syntax?
Say, to allow..
```
mystatement "Something"
```
Or,
```
new_if True:
print "example"
```
Not so much if you *should*, but rather if it's possible (short of modifying the python interpreters code) | One way to do things like this is to preprocess the source and modify it, translating your added statement to python. There are various problems this approach will bring, and I wouldn't recommend it for general usage, but for experimentation with language, or specific-purpose metaprogramming, it can occassionally be us... |
Can you add new statements to Python's syntax? | 214,881 | 72 | 2008-10-18T10:47:21Z | 216,795 | 15 | 2008-10-19T18:52:00Z | [
"python",
"syntax"
] | Can you add new statements (like `print`, `raise`, `with`) to Python's syntax?
Say, to allow..
```
mystatement "Something"
```
Or,
```
new_if True:
print "example"
```
Not so much if you *should*, but rather if it's possible (short of modifying the python interpreters code) | Yes, to some extent it is possible. There is a [module](http://entrian.com/goto/) out there that uses `sys.settrace()` to implement `goto` and `comefrom` "keywords":
```
from goto import goto, label
for i in range(1, 10):
for j in range(1, 20):
print i, j
if j == 3:
goto .end # breaking out from nested... |
Can you add new statements to Python's syntax? | 214,881 | 72 | 2008-10-18T10:47:21Z | 220,857 | 10 | 2008-10-21T05:26:58Z | [
"python",
"syntax"
] | Can you add new statements (like `print`, `raise`, `with`) to Python's syntax?
Say, to allow..
```
mystatement "Something"
```
Or,
```
new_if True:
print "example"
```
Not so much if you *should*, but rather if it's possible (short of modifying the python interpreters code) | General answer: you need to preprocess your source files.
More specific answer: install [EasyExtend](http://pypi.python.org/pypi/EasyExtend), and go through following steps
i) Create a new langlet ( extension language )
```
import EasyExtend
EasyExtend.new_langlet("mystmts", prompt = "my> ", source_ext = "mypy")
```... |
Can you add new statements to Python's syntax? | 214,881 | 72 | 2008-10-18T10:47:21Z | 4,572,994 | 7 | 2011-01-01T02:23:19Z | [
"python",
"syntax"
] | Can you add new statements (like `print`, `raise`, `with`) to Python's syntax?
Say, to allow..
```
mystatement "Something"
```
Or,
```
new_if True:
print "example"
```
Not so much if you *should*, but rather if it's possible (short of modifying the python interpreters code) | Here's a very simple but crappy way to add new statements, *in interpretive mode only*. I'm using it for little 1-letter commands for editing gene annotations using only sys.displayhook, but just so I could answer this question I added sys.excepthook for the syntax errors as well. The latter is really ugly, fetching th... |
Can you add new statements to Python's syntax? | 214,881 | 72 | 2008-10-18T10:47:21Z | 9,108,164 | 77 | 2012-02-02T06:39:44Z | [
"python",
"syntax"
] | Can you add new statements (like `print`, `raise`, `with`) to Python's syntax?
Say, to allow..
```
mystatement "Something"
```
Or,
```
new_if True:
print "example"
```
Not so much if you *should*, but rather if it's possible (short of modifying the python interpreters code) | You may find this useful - [Python internals: adding a new statement to Python](http://eli.thegreenplace.net/2010/06/30/python-internals-adding-a-new-statement-to-python/), quoted here:
---
This article is an attempt to better understand how the front-end of Python works. Just reading documentation and source code ma... |
What's a good library to manipulate Apache2 config files? | 215,542 | 7 | 2008-10-18T20:38:57Z | 215,552 | 7 | 2008-10-18T20:52:03Z | [
"java",
"python",
"perl",
"apache"
] | I'd like to create a script to manipulate Apache2 configuration directly, reading and writing its properties (like adding a new VirtualHost, changing settings of one that already exists).
Are there any libs out there, for Perl, Python or Java that automates that task? | Rather than manipulate the config files, you can use [mod\_perl](http://perl.apache.org/) to embed Perl directly into the config files. This could allow you, for example, to read required vhosts out of a database.
See [Configure Apache with Perl Example](http://perl.apache.org/start/tips/config.html) for quick example... |
What's a good library to manipulate Apache2 config files? | 215,542 | 7 | 2008-10-18T20:38:57Z | 215,695 | 7 | 2008-10-18T23:13:14Z | [
"java",
"python",
"perl",
"apache"
] | I'd like to create a script to manipulate Apache2 configuration directly, reading and writing its properties (like adding a new VirtualHost, changing settings of one that already exists).
Are there any libs out there, for Perl, Python or Java that automates that task? | In Perl, you've got at least 2 modules for that:
[Apache::ConfigFile](http://search.cpan.org/~nwiger/Apache-ConfigFile-1.18/ConfigFile.pm)
[Apache::Admin::Config](https://metacpan.org/pod/Apache%3a%3aAdmin%3a%3aConfig) |
What's the difference between a parent and a reference property in Google App Engine? | 215,570 | 10 | 2008-10-18T21:12:07Z | 215,902 | 8 | 2008-10-19T02:23:47Z | [
"python",
"api",
"google-app-engine"
] | From what I understand, the parent attribute of a db.Model (typically defined/passed in the constructor call) allows you to define hierarchies in your data models. As a result, this increases the size of the entity group. However, it's not very clear to me why we would want to do that. Is this strictly for ACID complia... | The only purpose of entity groups (defined by the parent attribute) is to enable transactions among different entities. If you don't need the transactions, don't use the entity group relationships.
I suggest you re-reading the [Keys and Entity Groups](http://code.google.com/appengine/docs/datastore/keysandentitygroups... |
What's the difference between a parent and a reference property in Google App Engine? | 215,570 | 10 | 2008-10-18T21:12:07Z | 216,187 | 15 | 2008-10-19T08:56:43Z | [
"python",
"api",
"google-app-engine"
] | From what I understand, the parent attribute of a db.Model (typically defined/passed in the constructor call) allows you to define hierarchies in your data models. As a result, this increases the size of the entity group. However, it's not very clear to me why we would want to do that. Is this strictly for ACID complia... | There are several differences:
* All entities with the same ancestor are in the same entity group. Transactions can only affect entities inside a single entity group.
* All writes to a single entity group are serialized, so throughput is limited.
* The parent entity is set on creation and is fixed. References can be c... |
What is the purpose of the colon before a block in Python? | 215,581 | 44 | 2008-10-18T21:18:46Z | 215,676 | 56 | 2008-10-18T22:49:32Z | [
"python",
"syntax"
] | What is the purpose of the colon before a block in Python?
Example:
```
if n == 0:
print "The end"
``` | The colon is there to declare the start of an indented block.
Technically, it's not necessary; you could just indent and de-indent when the block is done. However, based on the [Python koan](http://www.python.org/dev/peps/pep-0020/) âexplicit is better than implicitâ (EIBTI), I believe that Guido deliberately made... |
What is the purpose of the colon before a block in Python? | 215,581 | 44 | 2008-10-18T21:18:46Z | 216,060 | 12 | 2008-10-19T05:40:07Z | [
"python",
"syntax"
] | What is the purpose of the colon before a block in Python?
Example:
```
if n == 0:
print "The end"
``` | Three reasons:
1. To increase readability. The colon helps the code flow into the following indented block.
2. To help text editors/IDEs, they can automatically indent the next line if the previous line ended with a colon.
3. To make parsing by python slightly easier. |
What is the purpose of the colon before a block in Python? | 215,581 | 44 | 2008-10-18T21:18:46Z | 1,464,645 | 15 | 2009-09-23T08:13:16Z | [
"python",
"syntax"
] | What is the purpose of the colon before a block in Python?
Example:
```
if n == 0:
print "The end"
``` | Consider the following list of things to buy from the grocery store, written in Pewprikanese.
```
pewkah
lalala
chunkykachoo
pewpewpew
skunkybacon
```
When I read that, I'm confused, Are chunkykachoo and pewpewpew a kind of lalala? Or what if chunkykachoo and pewpewpew are indented just because they are speci... |
Why Python decorators rather than closures? | 215,689 | 13 | 2008-10-18T23:07:28Z | 215,782 | 7 | 2008-10-19T00:34:16Z | [
"python",
"decorator"
] | I still haven't got my head around decorators in Python.
I've already started using a lot of closures to do things like customize functions and classes in my coding.
Eg.
```
class Node :
def __init__(self,val,children) :
self.val = val
self.children = children
def makeRunner(f) :
def run(nod... | Are your examples real code, or just examples?
If they're real code, I think you overuse decorators, probably because of your background (i.e. you are used to other programming languages)
### Stage 1: avoiding decorators
```
def run(rootnode, func):
def _run(node): # recursive internal function
func(node... |
Why Python decorators rather than closures? | 215,689 | 13 | 2008-10-18T23:07:28Z | 335,442 | 13 | 2008-12-02T21:03:22Z | [
"python",
"decorator"
] | I still haven't got my head around decorators in Python.
I've already started using a lot of closures to do things like customize functions and classes in my coding.
Eg.
```
class Node :
def __init__(self,val,children) :
self.val = val
self.children = children
def makeRunner(f) :
def run(nod... | While it is true that syntactically, decorators are just "sugar", that is not the best way to think about them.
Decorators allow you to weave functionality into your existing code without actually modifying it. And they allow you to do it in a way that is declarative.
This allows you to use decorators to do *aspect-o... |
How do I coherently organize modules for a PyGTK desktop application? | 216,093 | 7 | 2008-10-19T06:07:28Z | 216,145 | 7 | 2008-10-19T07:39:33Z | [
"python",
"gtk",
"module",
"pygtk",
"organization"
] | I am working on a desktop application in PyGTK and seem to be bumping up against some limitations of my file organization. Thus far I've structured my project this way:
* application.py - holds the primary application class (most functional routines)
* gui.py - holds a loosely coupled GTK gui implementation. Handles s... | In the project [Wader](http://wader-project.org) we use [python gtkmvc](http://pygtkmvc.sourceforge.net/), that makes much easier to apply the MVC patterns when using pygtk and glade, you can see the file organization of our project in the [svn repository](http://trac.wader-project.org/browser/trunk/wader):
```
wader/... |
In Python, what does it mean if an object is subscriptable or not? | 216,972 | 109 | 2008-10-19T21:08:23Z | 216,980 | 102 | 2008-10-19T21:11:05Z | [
"python",
"terminology"
] | Which types of objects fall into the domain of "subscriptable"? | It basically means that the object implements the `__getitem__()` method. In other words, it describes objects that are "containers", meaning they contain other objects. This includes lists, tuples, and dictionaries. |
In Python, what does it mean if an object is subscriptable or not? | 216,972 | 109 | 2008-10-19T21:08:23Z | 217,081 | 20 | 2008-10-19T22:39:47Z | [
"python",
"terminology"
] | Which types of objects fall into the domain of "subscriptable"? | Off the top of my head, the following are the only built-ins that are subscriptable:
```
string: "foobar"[3] == "b"
tuple: (1,2,3,4)[3] == 4
list: [1,2,3,4][3] == 4
dict: {"a":1, "b":2, "c":3}["c"] == 3
```
But mipadi's answer is correct; any class that implements \_\_getitem\_\_ is subscriptable |
How can I determine the display idle time from Python in Windows, Linux, and MacOS? | 217,157 | 15 | 2008-10-19T23:25:08Z | 1,145,688 | 10 | 2009-07-17T21:07:04Z | [
"python",
"winapi",
"gtk",
"pygtk",
"pywin32"
] | I would like to know how long it's been since the user last hit a key or moved the mouse - not just in my application, but on the whole "computer" (i.e. display), in order to guess whether they're still at the computer and able to observe notifications that pop up on the screen.
I'd like to do this purely from (Py)GTK... | [Gajim](http://www.gajim.org/) does it this way on Windows, OS X and GNU/Linux (and other \*nixes):
1. [Python wrapper module](https://trac.gajim.org/browser/src/common/sleepy.py?rev=604c5de0dfe72dfa76b3014c410a50daae381cbe) (also includes Windows idle time detection code, using `GetTickCount` with `ctypes`);
2. [Ctyp... |
how to generate unit test code for methods | 217,900 | 3 | 2008-10-20T09:36:51Z | 217,925 | 7 | 2008-10-20T09:48:11Z | [
"python",
"unit-testing"
] | i want to write code for unit test to test my application code. I have different methods and now want to test these methods one by one in python script.
but i do not how to i write. can any one give me example of small code for unit testing in python.
i am thankful | Read the [unit testing framework section](http://www.python.org/doc/2.5.2/lib/module-unittest.html) of the [Python Library Reference](http://www.python.org/doc/2.5.2/lib/lib.html).
A [basic example](http://www.python.org/doc/2.5.2/lib/minimal-example.html) from the documentation:
```
import random
import unittest
cl... |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.