
title stringlengths 12 150 | question_id int64 469 40.1M | question_score int64 2 5.52k | question_date stringdate 2008-08-02 15:11:16 2016-10-18 06:16:31 | answer_id int64 536 40.1M | answer_score int64 7 8.38k | answer_date stringdate 2008-08-02 18:49:07 2016-10-18 06:19:33 | tags listlengths 1 5 | question_body_md stringlengths 15 30.2k | answer_body_md stringlengths 11 27.8k |
|---|---|---|---|---|---|---|---|---|---|
Dynamically setting __tablename__ for sharding in SQLAlchemy? | 19,163,911 | 7 | 2013-10-03T16:05:12Z | 19,168,545 | 9 | 2013-10-03T20:20:33Z | [
"python",
"mysql",
"orm",
"sqlalchemy"
] | In order to handle a growing database table, we are sharding on table name. So we could have database tables that are named like this:
```
table_md5one
table_md5two
table_md5three
```
All tables have the exact same schema.
How do we use SQLAlchemy and dynamically specify the **tablename** for the class that correspo... | OK, we went with the custom SQLAlchemy declaration rather than the declarative one.
So we create a dynamic table object like this:
```
from sqlalchemy import MetaData, Table, Column
def get_table_object(self, md5hash):
metadata = MetaData()
table_name = 'table_' + md5hash
table_object = Table(table_name,... |
python numpy/scipy curve fitting | 19,165,259 | 21 | 2013-10-03T17:16:51Z | 19,165,437 | 29 | 2013-10-03T17:27:22Z | [
"python",
"numpy",
"scipy",
"curve-fitting"
] | I have some points and I am trying to fit curve for this points. I know that there exist `scipy.optimize.curve_fit` function, but I do not understand documentation, i.e how to use this function.
My poits: `np.array([(1, 1), (2, 4), (3, 1), (9, 3)])`
Can anybody explain how to do that? | You'll first need to separate your numpy array into two separate arrays containing x and y values.
```
x = [1, 2, 3, 9]
y = [1, 4, 1, 3]
```
curve\_fit also requires a function that provides the type of fit you would like. For instance, a linear fit would use a function like
```
def func(x, a, b):
return a*x + b... |
python numpy/scipy curve fitting | 19,165,259 | 21 | 2013-10-03T17:16:51Z | 19,165,440 | 37 | 2013-10-03T17:27:30Z | [
"python",
"numpy",
"scipy",
"curve-fitting"
] | I have some points and I am trying to fit curve for this points. I know that there exist `scipy.optimize.curve_fit` function, but I do not understand documentation, i.e how to use this function.
My poits: `np.array([(1, 1), (2, 4), (3, 1), (9, 3)])`
Can anybody explain how to do that? | I suggest you to start with simple polynomial fit, `scipy.optimize.curve_fit` tries to fit a function `f` that you must know to a set of points.
This is a simple 3 degree polynomial fit using `numpy.polyfit` and `poly1d`, the first performs a least squares polynomial fit and the second calculates the new points:
```
... |
Removing JSON property in array of objects with Python | 19,167,485 | 9 | 2013-10-03T19:20:01Z | 19,167,546 | 18 | 2013-10-03T19:24:50Z | [
"python",
"json"
] | I have a JSON array that I'm cleaning up in Python. I want to remove the `imageData` property:
**data.json**
```
[{"title": "foo", "imageData": "xyz123"},
{"title": "bar", "imageData": "abc123"},
{"title": "baz", "imageData": "def456"}]
```
I am setting up a list comprehension to remove the property, but I'm not sur... | An easy solution to your problem is deleting the unwanted key in place, with `del`:
```
import json
with open('data.json') as json_data:
data = json.load(json_data)
for element in data:
del element['imageData']
```
You should add some safety checks, but you get the idea. |
Removing JSON property in array of objects with Python | 19,167,485 | 9 | 2013-10-03T19:20:01Z | 19,167,602 | 13 | 2013-10-03T19:27:53Z | [
"python",
"json"
] | I have a JSON array that I'm cleaning up in Python. I want to remove the `imageData` property:
**data.json**
```
[{"title": "foo", "imageData": "xyz123"},
{"title": "bar", "imageData": "abc123"},
{"title": "baz", "imageData": "def456"}]
```
I am setting up a list comprehension to remove the property, but I'm not sur... | If not all the elements have an `imageData` key, then using `del` will cause an `KeyError` exception. You could guard against that by using `pop` with a default:
```
for item in data:
item.pop('image', None)
``` |
Prevent or dismiss 'empty file' warning in loadtxt | 19,167,550 | 6 | 2013-10-03T19:24:57Z | 19,167,903 | 9 | 2013-10-03T19:44:15Z | [
"python",
"numpy"
] | My code goes through a number of files reading them into lists with the command:
```
data = np.loadtxt(myfile, unpack=True)
```
Some of these files are empty (I can't control that) and when that happens I get this warning printed on screen:
```
/usr/local/lib/python2.7/dist-packages/numpy/lib/npyio.py:795: UserWarni... | You will have to wrap the line with `catch_warnings`, then call the `simplefilter` method to suppress those warnings. For example:
```
with warnings.catch_warnings():
warnings.simplefilter("ignore")
data = np.loadtxt(myfile, unpack=True)
```
Should do it. |
"Python version 2.7 required, which was not found in the registry" error when attempting to install netCDF4 on Windows 8 | 19,169,582 | 28 | 2013-10-03T21:31:13Z | 23,418,442 | 54 | 2014-05-01T23:32:34Z | [
"python",
"windows",
"python-2.7",
"install",
"package"
] | I use Anaconda 1.7, 32 bit. I downloaded the correct version of the netCDF4 installer from [here](https://code.google.com/p/netcdf4-python/downloads/list).
I attempted to copy the HKEY\_LOCAL\_MACHINE\SOFTWARE\Python folder into HKEY\_LOCAL\_MACHINE\SOFTWARE\Wow6432Node. No luck.
Does anyone have any idea why this mi... | This error can occur if you are installing a package with a different bitness than your Python version. To see whether your Python installation is 32- or 64-bit, see [here](http://stackoverflow.com/a/10966396/1397061). |
"Python version 2.7 required, which was not found in the registry" error when attempting to install netCDF4 on Windows 8 | 19,169,582 | 28 | 2013-10-03T21:31:13Z | 29,633,714 | 17 | 2015-04-14T17:25:34Z | [
"python",
"windows",
"python-2.7",
"install",
"package"
] | I use Anaconda 1.7, 32 bit. I downloaded the correct version of the netCDF4 installer from [here](https://code.google.com/p/netcdf4-python/downloads/list).
I attempted to copy the HKEY\_LOCAL\_MACHINE\SOFTWARE\Python folder into HKEY\_LOCAL\_MACHINE\SOFTWARE\Wow6432Node. No luck.
Does anyone have any idea why this mi... | I had the same issue when using an .exe to install a Python package (because I use Anaconda and it didn't add Python to the registry). I fixed the problem by running this script:
```
#
# script to register Python 2.0 or later for use with
# Python extensions that require Python registry settings
#
# written by Joakim... |
Using str.contains() in pandas with dataframes | 19,169,649 | 6 | 2013-10-03T21:35:36Z | 19,170,098 | 14 | 2013-10-03T22:14:31Z | [
"python",
"pandas",
"contains"
] | I'm wondering if there is a more efficient way to use the str.contains() function in Pandas, to search for two partial strings at once. I want to search a given column in a dataframe for data that contains either "nt" or "nv". Right now, my code looks like this:
```
df[df['Behavior'].str.contains("nt", na=False)]
... | The is one regular expression and should be in one string:
```
"nt|nv" # rather than "nt" | " nv"
f_recs[f_recs['Behavior'].str.contains("nt|nv", na=False)]
```
Python doesn't let you use the or (`|`) operator on strings:
```
In [1]: "nt" | "nv"
TypeError: unsupported operand type(s) for |: 'str' and 'str'
``` |
Converting well number to the identifier on a 96 well plate | 19,170,420 | 2 | 2013-10-03T22:45:40Z | 19,170,441 | 7 | 2013-10-03T22:47:54Z | [
"python",
"bioinformatics"
] | In a 96 well plate there are 8 columns (A,B,...) and 12 rows (01 ... 12);
so the plate looks like this:
```
A01 A02 ... A12
B01 B02 ... B12
C01 ...
...
H01 ..
```
Currently I have identified the plates as:
```
1 2 3 4 ... 12
13 14 15 ...24
..
84 ... 96
```
How can I write a function `wellnumber2wellidentif... | Oh sure, go and make it 1-based why don't you...
```
'ABCDEFGH'[(num - 1) // 12] + '%02d' % ((num - 1) % 12 + 1,)
``` |
Plotting data from csv using matplotlib.pyplot | 19,170,511 | 2 | 2013-10-03T22:55:40Z | 19,170,627 | 9 | 2013-10-03T23:08:42Z | [
"python",
"csv",
"python-2.7",
"matplotlib"
] | I am trying to follow a tutorial on youtube, now in the tutorial they plot some standard text files using matplotlib.pyplot, I can achieve this easy enough, however I am now trying to perform the same thing using some csvs I have of real data.
The code I am using is import matplotlib.pyplot as plt
import csv
#import n... | `csv.reader()` returns strings (technically, `.next()`method of reader object returns lists of strings). Without converting them to `float` or `int`, you won't be able to `plt.plot()` them.
To save the trouble of converting, I suggest using `genfromtxt()` from `numpy`. (<http://docs.scipy.org/doc/numpy/reference/gener... |
Printing a string prints 'u' before the string in Python? | 19,170,808 | 3 | 2013-10-03T23:30:39Z | 19,171,251 | 7 | 2013-10-04T00:25:52Z | [
"python",
"unicode",
"printing"
] | 'u' before elements in printed list? I didn't type u in my code.
```
hobbies = []
#prompt user three times for hobbies
for i in range(3):
hobby = raw_input('Enter a hobby:')
hobbies.append(hobby)
#print list stored in hobbies
print hobbies
```
When I run this, it prints the list but it is formatted like thi... | I think what you're actually surprised by here is that printing a single string doesn't do the same thing as printing a list of stringsâand this is true whether they're Unicode or not:
```
>>> hobby1 = u'Dizziness'
>>> hobby2 = u'Vértigo'
>>> hobbies = [hobby1, hobby2]
>>> print hobby1
Dizziness
>>> print hobbies
[... |
If Python is executed one line at a time, why can it see variables before they're declared? | 19,171,477 | 4 | 2013-10-04T00:57:17Z | 19,171,515 | 7 | 2013-10-04T01:01:56Z | [
"python",
"python-3.x",
"compilation",
"scope"
] | ```
x = 4
def test():
print(x)
x = 2
test()
```
This gives an error because when you go to `print(x)`, it sees that you have `x` declared in the scope of the function `test`, and it tells you you're trying to reference it without having declared it.
I know that if I do `global x` it's no problem, or if I move... | Who told you Python is executed one line at a time? Python is executed one bytecode at a time. And that bytecode comes from the compiler, which operates one *statement* at a time. Statements can be multiple lines. And a function definition is a statement.
So, one of the first steps in compiling a function definition i... |
Send e-mail to Gmail with inline image using Python | 19,171,742 | 7 | 2013-10-04T01:30:40Z | 20,485,764 | 13 | 2013-12-10T03:57:21Z | [
"python",
"image",
"email",
"gmail",
"mime"
] | My objective is to use Python to send an e-mail to a Gmail user that has an inline image. It is not possible to host this image online and then link to it through a `href`, due to the sensitive nature of the images (data from my work).
I've tried encoding the `base64` version into a `HTML` then sending th is `HTML`, b... | It seems that following the gmail email template works:
```
* multipart/related
- multipart/alternative
+ text/plain
+ text/html
<div dir="ltr"><img src="cid:ii_xyz" alt"..."><br></div>
- image/jpeg
Content-ID: <ii_xyz>
```
Based on [Send an HTML email with embedded image and plain text alternat... |
Python - is it possible to set a variable to an operator? | 19,171,969 | 2 | 2013-10-04T01:57:41Z | 19,171,984 | 7 | 2013-10-04T02:00:11Z | [
"python",
"variables",
"operation"
] | I'm developing a bunch of functions that have the same basic structure - they take two lists and use a loop to do a particular operation pairwise for the two lists (for example, one will take each element of a list raised to the power represented by the corresponding element in the second list).
Since all of these fun... | Yes! You want the `operator` module, which "exposes Python's intrinsic operators as efficient functions."
```
import operator
op = operator.add
var = op(5, 7)
```
As @falsetru points out, a lambda is handy too; the functions in `operator` are going to be a wee bit faster, though:
```
from timeit import timeit
print... |
How to create only one table with SQLAlchemy? | 19,175,311 | 16 | 2013-10-04T07:08:33Z | 19,175,907 | 9 | 2013-10-04T07:43:10Z | [
"python",
"mysql",
"python-3.x",
"sqlalchemy"
] | I am unable to create a single table using SQLAlchemy.
I can create it by calling `Base.metadata.create_all(engine)` but as the number of table grows, this call takes a long time.
I create table classes on the fly and then populate them.
```
from sqlalchemy import create_engine, Column, Integer, Sequence, String, Da... | > Above, the declarative\_base() callable returns a new base class from
> which all mapped classes should inherit. When the class definition is
> completed, a new Table and mapper() will have been generated.
>
> The resulting table and mapper are accessible via `__table__` and
> `__mapper__` attributes
(From [here](ht... |
Selecting Data between Specific hours in a pandas dataframe | 19,179,214 | 5 | 2013-10-04T10:38:49Z | 19,180,651 | 10 | 2013-10-04T11:58:42Z | [
"python",
"pandas",
"time-series"
] | My Pandas Dataframe frame looks something like this
```
1. 2013-10-09 09:00:05
2. 2013-10-09 09:05:00
3. 2013-10-09 10:00:00
4. ............
5. ............
6. ............
7. 2013-10-10 09:00:05
8. 2013-10-10 09:05:00
9. 2013-10-10 10:00:00
```
I want the data lying in between hours 9 and 10 ...if any... | ```
In [7]: index = date_range('20131009 08:30','20131010 10:05',freq='5T')
In [8]: df = DataFrame(randn(len(index),2),columns=list('AB'),index=index)
In [9]: df
Out[9]:
<class 'pandas.core.frame.DataFrame'>
DatetimeIndex: 308 entries, 2013-10-09 08:30:00 to 2013-10-10 10:05:00
Freq: 5T
Data columns (total 2 column... |
python: importlib.import_module("time") but time is not defined globally | 19,179,269 | 2 | 2013-10-04T10:41:37Z | 19,179,497 | 7 | 2013-10-04T10:55:14Z | [
"python",
"python-2.7",
"python-import"
] | In order to add to my program (in python 2.7) a check for available modules, I added the following code in place of the classical import (the idea being to help someone to locate & add extra modules):
```
mymodules = ['socket', 'requests', 'simplejson', 'pickle', 'IPy',
'pygeoip', 'urllib', 'time', 'urllib2', 'Str... | From the [docs](http://docs.python.org/2.7/library/importlib.html):
> The specified module will be inserted into `sys.modules` and returned.
In other words, `import_module` will not create a variable for you, you will have to do it yourself:
```
time = importlib.import_module('time')
```
Or, in your "dynamic" case:... |
How do I get an older version of Django? Pip says could not find version | 19,179,881 | 9 | 2013-10-04T11:17:20Z | 19,180,047 | 8 | 2013-10-04T11:25:28Z | [
"python",
"django"
] | I need Django 0.96. I have a huge Django project which I need to run, but it's very very tied to 0.96, I could take a looot of time to port it 1.x
When I do `pip install django==0.96` I get this
```
Could not find a version that satisfies the requirement django==0.96 (from versions: 1.1.3, 1.1.4, 1.2.1, 1.2.2, 1.2.3,... | That old version is not available on pip. Here are the links to versions of branch 0.96.x: [0.96.5](https://www.djangoproject.com/m/releases/0.96/Django-0.96.5.tar.gz), [0.96.4](https://www.djangoproject.com/m/releases/0.96/Django-0.96.4.tar.gz), [0.96.3](https://www.djangoproject.com/m/releases/0.96/Django-0.96.3.tar.... |
How do I get an older version of Django? Pip says could not find version | 19,179,881 | 9 | 2013-10-04T11:17:20Z | 19,180,081 | 8 | 2013-10-04T11:27:50Z | [
"python",
"django"
] | I need Django 0.96. I have a huge Django project which I need to run, but it's very very tied to 0.96, I could take a looot of time to port it 1.x
When I do `pip install django==0.96` I get this
```
Could not find a version that satisfies the requirement django==0.96 (from versions: 1.1.3, 1.1.4, 1.2.1, 1.2.2, 1.2.3,... | You can install from git repo:
```
pip install git+https://github.com/django/django@c939b2a1cb22b5035b1ccf90ee7686f334e6049d#egg=django==0.96.5
``` |
PyXML install - memmove does not exist on this platform | 19,181,102 | 9 | 2013-10-04T12:24:58Z | 19,305,535 | 17 | 2013-10-10T20:24:51Z | [
"python",
"gcc"
] | Im trying to install pyxml library with pip but i get following errors during installation:
```
extensions/expat/lib/xmlparse.c:75:2: error: #error memmove does not exist on this platform, nor is a substitute available
```
I've tried to reinstall gcc compilator .
Current version i've is: **gcc (Ubuntu/Linaro 4.7.3-1... | I had the same problem, also running kubuntu-13.04 (worked fine in 12.10.)
@volferine seems to be onto something. My `config_h` file is also `/usr/include/python2.7/pyconfig.h`, and it did not contain the string `HAVE_MEMMOVE`.
To `pyconfig.h`, I appended:
```
#define HAVE_MEMMOVE 1
```
PyXML now appears to build f... |
Splitting Image using OpenCV in python | 19,181,485 | 2 | 2013-10-04T12:43:04Z | 19,181,594 | 8 | 2013-10-04T12:48:24Z | [
"python",
"opencv",
"python-2.7"
] | I have aN image and want to split it into three RGB channel images using CV2 in python.
I also want the good documentation where i can find the all function of openCV as I am new to OpenCV completely. | That is as simple as loading an image using `cv2.imread` and then use `cv2.split`:
```
>>> import cv2
>>> import numpy as np
>>> img = cv2.imread("foo.jpg")
>>> b,g,r = cv2.split(img)
```
OpenCV documentation is available from [docs.opencv.org](http://docs.opencv.org/) |
Bisect a Python List and finding the Index | 19,182,281 | 7 | 2013-10-04T13:20:47Z | 19,182,306 | 15 | 2013-10-04T13:21:46Z | [
"python",
"list",
"python-2.x",
"bisection"
] | When I use the `bisect_left()` function, why do I not get the `index` of the element, but instead `index + 1`?
```
import bisect
t3 = ['carver', 'carvers', 'carves', 'carving', 'carvings']
print bisect.bisect(t3, 'carves') // 3
print bisect.bisect(t3, 'carving') // 4
print bisect.bisect(t3, 'carver') // 1
``` | `bisect.bisect()` is a shorter name for [`bisect.bisect_right()`](http://docs.python.org/2/library/bisect.html#bisect.bisect_right), **not** `bisect.bisect_left()`.
You'll need to use the full name, `bisect.bisect_left()`, instead:
```
>>> import bisect
>>> t3 = ['carver', 'carvers', 'carves', 'carving', 'carvings']
... |
How to sort in python with multiple conditions? | 19,182,895 | 2 | 2013-10-04T13:47:36Z | 19,183,195 | 7 | 2013-10-04T14:00:05Z | [
"python",
"sorting"
] | I have a list with sublists as follows:
```
result = [ ['helo', 10], ['bye', 50], ['yeah', 5], ['candy',30] ]
```
I want to sort this with three conditions:
first, by highrest integer in index 2 of sublist, then by length of word in index 1 of sublist, and finally by alphabetical order in the 1st index of sublist.
I... | every element is a list of 2 elements, sorting by the length of the list is useless because all of them has the same length, maybe you want to sort by the length of the first element so
```
finalresult = sorted(result, key=lambda word: (-word[1], len(word[0]), word[0]))
``` |
Global variable and python flask | 19,182,963 | 6 | 2013-10-04T13:49:50Z | 19,183,117 | 8 | 2013-10-04T13:56:47Z | [
"python",
"flask",
"global-variables"
] | What i want to do is just display the firstevent from one API. The variable is called âfirsteventâ and the value should display on the webpage. But firstevent is inside a def, so i change it into a global variable and hope it can be used across different functions. But it shows âNameError: global name 'firstevent... | Yep, it's a scope problem. In the beginning of your `main()` function, add this:
```
global firstevent
```
That should done it. Any variable that is not defined inside a function, is a global. You can access it straightly from any function. However, to modify the variable you'll need to write `global var` in your fun... |
Pandas: Read a CSV of timeseries data with 'column' header as row element | 19,183,304 | 3 | 2013-10-04T14:04:33Z | 19,183,683 | 12 | 2013-10-04T14:23:44Z | [
"python",
"csv",
"pandas",
"time-series"
] | Is it possible to read a CSV file in this format:
```
2013-01-01,A,1
2013-01-02,A,2
2013-01-03,A,3
2013-01-04,A,4
2013-01-05,A,5
2013-01-01,B,1
2013-01-02,B,2
2013-01-03,B,3
2013-01-04,B,4
2013-01-05,B,5
```
into a DataFrame that ends up like this:
```
A B
2013-01-01 1 1
2013-01-02 2 2
2013-01... | Why not reshape (pivot) *after* you've read in the DataFrame?
```
In [1]: df = pd.read_csv('foo.csv', sep=',', parse_dates=[0], header=None,
names=['Date', 'letter', 'value'])
In [2]: df
Out[2]:
Date letter value
0 2013-01-01 00:00:00 A 1
1 2013-01-02 00:00:00 ... |
How to add group labels for bar charts in matplotlib? | 19,184,484 | 11 | 2013-10-04T14:59:34Z | 19,242,176 | 23 | 2013-10-08T07:57:48Z | [
"python",
"matplotlib",
"bar-chart"
] | I want to plot data of the following form using matplotlib's bar plot feature:
```
data = {'Room A':
{'Shelf 1':
{'Milk': 10,
'Water': 20},
'Shelf 2':
{'Sugar': 5,
'Honey': 6}
},
'Room B':
{'Shelf 1':
... | Since I could not find a built-in solution for this in matplotlib, I coded my own:
```
#!/usr/bin/env python
from matplotlib import pyplot as plt
def mk_groups(data):
try:
newdata = data.items()
except:
return
thisgroup = []
groups = []
for key, value in newdata:
newgroup... |
Pythonic list comprehension possible with this loop? | 19,185,128 | 15 | 2013-10-04T15:30:32Z | 19,185,231 | 29 | 2013-10-04T15:35:21Z | [
"python",
"loops",
"list-comprehension"
] | I have a love/hate relationship with list comprehension. On the one hand I think they are neat and elegant. On the other hand I hate reading them. (especially ones I didn't write) I generally follow the rule of, make it readable until speed is required. So my question is really academic at this point.
I want a list of... | There is - create a generator of the stripped strings first, then use that:
```
stations = [row for row in (row.strip() for row in data) if row]
```
You could also write it without a comp, eg (swap to `imap` and remove `list` for Python 2.x):
```
stations = list(filter(None, map(str.strip, data)))
``` |
Pythonic list comprehension possible with this loop? | 19,185,128 | 15 | 2013-10-04T15:30:32Z | 19,185,252 | 13 | 2013-10-04T15:36:33Z | [
"python",
"loops",
"list-comprehension"
] | I have a love/hate relationship with list comprehension. On the one hand I think they are neat and elegant. On the other hand I hate reading them. (especially ones I didn't write) I generally follow the rule of, make it readable until speed is required. So my question is really academic at this point.
I want a list of... | Nested comprehensions can be tricky to read, so my first preference would be:
```
stripped = (x.strip() for x in data)
stations = [x for x in stripped if x]
```
Or, if you inline `stripped`, you get a single (nested) list comprehension:
```
stations = [x for x in (x.strip() for x in data) if x]
```
Note that the fi... |
Get last item from a list as integer/float | 19,185,696 | 2 | 2013-10-04T15:59:48Z | 19,185,717 | 10 | 2013-10-04T16:00:36Z | [
"python",
"list"
] | Very simple question, I have a list like so:
```
a = [0,1,2,3,4,5,7,8]
```
and I need to get the last item in that list as a float or an integer. If I do:
```
print a[0], a[4]
```
I get `1 5`, which is fine, but if i try to retrieve the last item with:
```
print a[-1:]
```
I get the *list* `[8]` instead of the *n... | You need to do `a[-1]` to get the last item. See below:
```
>>> a = [0,1,2,3,4,5,7,8]
>>> a[-1]
8
>>>
```
Having the colon in there makes it *slice* the list, not index it.
Here are some references on lists and slicing/indexing them:
<http://docs.python.org/2/tutorial/introduction.html#lists>
[Python's slice notat... |
Performance when passing huge list as argument in recursive function? | 19,187,785 | 2 | 2013-10-04T17:58:47Z | 19,187,912 | 7 | 2013-10-04T18:05:38Z | [
"python",
"performance",
"recursion",
"argument-passing"
] | I am using Python and I have a recursive function that takes a huge list as one of the arguments:
```
# Current implementation
def MyFunction(arg1, arg2, my_huge_list)
...
...
MyFunction(new_arg1, new_arg2, my_huge_list)
```
As you can see above, `MyFunction` is called recursively using the *same* list `m... | The list will be passed by reference, so it doesn't take any longer to transfer a 1-item list vs. a 100000 item list:
```
def null(x): return x
longlist = range(100000)
shortlist = range(1)
longerlist = range(1000000)
%timeit null(shortlist)
10000000 loops, best of 3: 124 ns per loop
%timeit null(longlist)
10000000 ... |
defaultdict of defaultdict, nested | 19,189,274 | 36 | 2013-10-04T19:28:50Z | 19,189,356 | 51 | 2013-10-04T19:33:55Z | [
"python",
"recursion",
"defaultdict"
] | Is there a way to make a defaultdict also be the default for the defaultdict?
IOW, if I do:
```
x = defaultdict(...stuff...)
x[0][1][0]
{}
```
That's what I want. I'll probably just end up using the bunch pattern, but when i realized i didn't know how to do this, it got me interested.
So, I can do:
```
x = defaultd... | For an arbitrary number of levels:
```
def rec_dd():
return defaultdict(rec_dd)
>>> x = rec_dd()
>>> x['a']['b']['c']['d']
defaultdict(<function rec_dd at 0x7f0dcef81500>, {})
>>> print json.dumps(x)
{"a": {"b": {"c": {"d": {}}}}}
```
Of course you could also do this with a lambda, but I find lambdas to be less ... |
defaultdict of defaultdict, nested | 19,189,274 | 36 | 2013-10-04T19:28:50Z | 19,189,366 | 17 | 2013-10-04T19:34:18Z | [
"python",
"recursion",
"defaultdict"
] | Is there a way to make a defaultdict also be the default for the defaultdict?
IOW, if I do:
```
x = defaultdict(...stuff...)
x[0][1][0]
{}
```
That's what I want. I'll probably just end up using the bunch pattern, but when i realized i didn't know how to do this, it got me interested.
So, I can do:
```
x = defaultd... | There is a nifty trick for doing that:
```
tree = lambda: defaultdict(tree)
```
Then you can create your `x` with `x = tree()`. |
defaultdict of defaultdict, nested | 19,189,274 | 36 | 2013-10-04T19:28:50Z | 19,189,781 | 11 | 2013-10-04T20:01:29Z | [
"python",
"recursion",
"defaultdict"
] | Is there a way to make a defaultdict also be the default for the defaultdict?
IOW, if I do:
```
x = defaultdict(...stuff...)
x[0][1][0]
{}
```
That's what I want. I'll probably just end up using the bunch pattern, but when i realized i didn't know how to do this, it got me interested.
So, I can do:
```
x = defaultd... | Similar to BrenBarn's solution, but doesn't contain the name of the variable `tree` twice, so it works even after changes to the variable dictionary:
```
tree = (lambda f: f(f))(lambda a: (lambda: defaultdict(a(a))))
```
Then you can create each new `x` with `x = tree()`.
---
For the `def` version, we can use funct... |
defaultdict of defaultdict, nested | 19,189,274 | 36 | 2013-10-04T19:28:50Z | 27,809,959 | 33 | 2015-01-07T01:11:08Z | [
"python",
"recursion",
"defaultdict"
] | Is there a way to make a defaultdict also be the default for the defaultdict?
IOW, if I do:
```
x = defaultdict(...stuff...)
x[0][1][0]
{}
```
That's what I want. I'll probably just end up using the bunch pattern, but when i realized i didn't know how to do this, it got me interested.
So, I can do:
```
x = defaultd... | The other answers here tell you how to create a `defaultdict` which contains "infinitely many" `defaultdict`, but they fail to address what I think may have been your initial need which was to simply have a two-depth defaultdict.
You may have been looking for:
```
defaultdict(lambda: defaultdict(dict))
```
The reaso... |
Getting the r-squared value using curve_fit | 19,189,362 | 4 | 2013-10-04T19:34:10Z | 37,899,817 | 7 | 2016-06-18T17:33:13Z | [
"python",
"matplotlib",
"scipy"
] | I am a beginner with both Python and all its libs. But I have managed to make a small program that works as intended.
It takes a string, counts the occurence of the different letters and plots them in a graph and then applies a equation and its curve.¨
Now i would like to get the r-squared value of the fit.
The overa... | **Computing 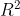:**
The 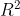 value can be found using the *mean* (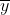), the *total sum of squares* ( indicates that your program exited due to receiving signal 9, which is `SIGKILL`. This also explains the `killed` message. The question is, why did you receive that signal?
The most likely reason is probably that your process crossed some limit in the amount of system resources that you are allow... |
Setting Django up to use MySQL | 19,189,813 | 80 | 2013-10-04T20:03:20Z | 19,189,930 | 149 | 2013-10-04T20:09:55Z | [
"python",
"mysql",
"django",
"debian"
] | I'm wanting to move away from PHP a little ways and learn Python. In order to do web development with Python I'm going to need a framework to help with templating and other things.
I have a non-production server that I test all of web development stuff on. It is a Debian 7.1 LAMP stack that runs MariaDB instead of the... | [MySQL support](https://docs.djangoproject.com/en/dev/ref/databases/#mysql-notes) is simple to add. In your `DATABASES` array, you will have an entry like this:
```
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.mysql',
'NAME': 'DB_NAME',
'USER': 'DB_USER',
'PASSWORD': 'D... |
Setting Django up to use MySQL | 19,189,813 | 80 | 2013-10-04T20:03:20Z | 25,569,814 | 13 | 2014-08-29T13:56:22Z | [
"python",
"mysql",
"django",
"debian"
] | I'm wanting to move away from PHP a little ways and learn Python. In order to do web development with Python I'm going to need a framework to help with templating and other things.
I have a non-production server that I test all of web development stuff on. It is a Debian 7.1 LAMP stack that runs MariaDB instead of the... | To the very first please run the below commands to install python dependencies otherwise python runserver command will throw error.
```
sudo apt-get install libmysqlclient-dev
sudo pip install MySQL-python
```
Then configure the settings.py file as defined by #Andy and at the last execute :
```
python manage.py runs... |
Setting Django up to use MySQL | 19,189,813 | 80 | 2013-10-04T20:03:20Z | 27,270,303 | 7 | 2014-12-03T11:14:43Z | [
"python",
"mysql",
"django",
"debian"
] | I'm wanting to move away from PHP a little ways and learn Python. In order to do web development with Python I'm going to need a framework to help with templating and other things.
I have a non-production server that I test all of web development stuff on. It is a Debian 7.1 LAMP stack that runs MariaDB instead of the... | As all said above, you can easily install xampp first from <https://www.apachefriends.org/download.html>
Then follow the instructions as:
1. Install and run xampp from <http://www.unixmen.com/install-xampp-stack-ubuntu-14-04/>, then start Apache Web Server and MySQL Database from the GUI.
2. You can configure your web... |
Python fastest access to line in file | 19,189,961 | 13 | 2013-10-04T20:11:47Z | 19,190,196 | 13 | 2013-10-04T20:27:49Z | [
"python",
"performance",
"file",
"io"
] | I have an ASCII table in a file from which I want to read a particular set of lines (e.g. lines 4003 to 4005). The issue is that this file could be very very long (e.g. 100's of thousands to millions of lines), and I'd like to do this as quickly as possible.
**Bad Solution**: Read in the entire file, and go to those l... | I would probably just use [`itertools.islice`](http://docs.python.org/2/library/itertools.html#itertools.islice). Using islice over an iterable like a file handle means the whole file is never read into memory, and the first 4002 lines are discarded as quickly as possible. You could even cast the two lines you need int... |
Any ideas why R and Python's NumPy scaling of vectors is not matching? | 19,191,536 | 9 | 2013-10-04T22:06:44Z | 19,191,871 | 14 | 2013-10-04T22:41:23Z | [
"python",
"numpy",
"floating-accuracy"
] | I have the following Python code and output:
```
>>> import numpy as np
>>> s = [12.40265325, -1.3362417499999921, 6.8768662500000062, 25.673127166666703, 19.733372250000002, 21.649556250000003, 7.1676752500000021, -0.85349583333329804, 23.130314250000012, 20.074925250000007, -0.29701574999999281, 17.078694250000012, ... | For the `std`, which is clearly off by some substantial amount, in `numpy`, `std` returns `sqrt(sum((x-x.mean())**2)) / (n-ddof)` where `ddof=0` by default. I guess `R` assumes `ddof=1`, because:
```
In [7]: s.std()
Out[7]: 12.137473069268983
In [8]: s.std(ddof=1)
Out[8]: 12.255890244843339
```
and:
```
> sd(s)
[1]... |
Any ideas why R and Python's NumPy scaling of vectors is not matching? | 19,191,536 | 9 | 2013-10-04T22:06:44Z | 19,192,686 | 9 | 2013-10-05T00:26:58Z | [
"python",
"numpy",
"floating-accuracy"
] | I have the following Python code and output:
```
>>> import numpy as np
>>> s = [12.40265325, -1.3362417499999921, 6.8768662500000062, 25.673127166666703, 19.733372250000002, 21.649556250000003, 7.1676752500000021, -0.85349583333329804, 23.130314250000012, 20.074925250000007, -0.29701574999999281, 17.078694250000012, ... | This sheds light on some of it, using plain Python, with the `s` list as given in the original post:
```
>>> import math
>>> sum(s) / len(s)
1.3664283380001927e-14
>>> math.fsum(s) / len(s)
1.2434497875801753e-14
```
The first output reproduces `np.mean()`, and the second reproduces the R `mean()` (I'm sure that if t... |
Get psycopg2 count(*) number of results | 19,191,766 | 5 | 2013-10-04T22:29:36Z | 19,191,812 | 9 | 2013-10-04T22:35:17Z | [
"python",
"postgresql",
"psycopg2"
] | Whats the correct way to get the number or rows returned by this query? I'm specifically looking to see if no results are returned.
```
sql = 'SELECT count(*) from table WHERE guid = %s;'
data=[guid]
cur.execute(sql,data)
results = cur.fetchone()
for r in results:
print type(r) # Returns as string {'count': 0L} Or {... | `results` is itself a row object, in your case (judging by the claimed `print` output), a dictionary (you probably configured a [dict-like cursor subclass](http://initd.org/psycopg/docs/extras.html#dictionary-like-cursor)); simply access the `count` key:
```
result = cur.fetchone()
print result['count']
```
Because y... |
What difference between pickle and _pickle in python 3? | 19,191,859 | 13 | 2013-10-04T22:40:25Z | 19,191,885 | 22 | 2013-10-04T22:43:21Z | [
"python",
"serialization",
"python-3.x"
] | I am new in python and want implement **fast** object serialization. I was trying to use json, but it was too slow, also was trying to use marshall module, but the size of the objects serialized by marshall 6-7 times more than pickle, so i decided to use pickle in my project. I read about cPickle module, read that it q... | The `pickle` module **already** imports `_pickle` if available. It is the C-optimized version of the `pickle` module, and is used transparently.
From the [`pickle.py` source code](http://hg.python.org/cpython/file/bfebfadfc4aa/Lib/pickle.py#l1348):
```
# Use the faster _pickle if possible
try:
from _pickle import... |
AttributeError: 'module' object has no attribute 'utcnow' | 19,192,209 | 6 | 2013-10-04T23:22:30Z | 19,192,228 | 13 | 2013-10-04T23:24:40Z | [
"python",
"datetime"
] | When I input the simple code:
```
import datetime
datetime.utcnow()
```
, I was given error message:
```
Traceback (most recent call last):
File "<pyshell#1>", line 1, in <module>
datetime.utcnow()
AttributeError: 'module' object has no attribute 'utcnow'
```
But python's document of `utcnow` is just here: <h... | You are confusing the module with the type.
Use either:
```
import datetime
datetime.datetime.utcnow()
```
or use:
```
from datetime import datetime
datetime.utcnow()
```
e.g. either reference the `datetime` type in the `datetime` module, or import that type into your namespace from the module. If you use the la... |
Using Mutagen to process all accepted file types | 19,193,551 | 4 | 2013-10-05T03:08:41Z | 19,203,187 | 7 | 2013-10-05T22:01:39Z | [
"python",
"audio",
"audio-processing",
"mutagen",
"audioformat"
] | What do I need to do in order to process every file type accepted by mutagen, .ogg, .apev2, .wma, flac, mp4, and asf? (I excluded mp3 because it has the most documentation on it)
I'd appreciated if someone who know how this is done could provide some pseudo-code in order to explain the techniques used. The main tags t... | Each tag type has different names for the fields, and they don't all map perfectly.
If you just want a handful of the most important fields, Mutagen has "easy" wrappers for ID3v2 and MP4/ITMF. So, for example, you can do this:
```
>>> m = mutagen.File(path, easy=True)
>>> m['title']
[u'Sunshine Smile']
>>> m['artist'... |
Python: How to check if a network port is open on linux? | 19,196,105 | 21 | 2013-10-05T09:24:03Z | 19,196,218 | 48 | 2013-10-05T09:38:24Z | [
"python",
"linux",
"port",
"netstat"
] | How can I know if a certain port is open/closed on linux ubuntu, not a remote system, using python?
How can I list these open ports in python?
* Netstat:
Is there a way to integrate netstat output with python? | You can using the [socket module](http://docs.python.org/2/library/socket.html) to simply check if a port is open or not.
It would look something like this.
```
import socket;
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
result = sock.connect_ex(('127.0.0.1',80))
if result == 0:
print "Port is open"
el... |
Python: How to check if a network port is open on linux? | 19,196,105 | 21 | 2013-10-05T09:24:03Z | 29,287,391 | 9 | 2015-03-26T19:39:04Z | [
"python",
"linux",
"port",
"netstat"
] | How can I know if a certain port is open/closed on linux ubuntu, not a remote system, using python?
How can I list these open ports in python?
* Netstat:
Is there a way to integrate netstat output with python? | If you only care about the local machine, you can rely on the psutil package. You can either:
1. Check all ports used by a specific pid:
```
proc = psutil.Process(pid)
print proc.connections()
```
2. Check all ports used on the local machine:
```
print psutil.net_connections()
```
It works on W... |
Scikit Learn - K-Means - Elbow - criterion | 19,197,715 | 6 | 2013-10-05T12:19:24Z | 19,197,932 | 8 | 2013-10-05T12:41:25Z | [
"python",
"data-mining",
"cluster-analysis",
"scikit-learn",
"k-means"
] | Today i'm trying to learn something about K-means. I Have understand the algorithm and i know how it works. Now i'm looking for the right k... I found the elbow criterion as a method to detect the right k but i do not understand how to use it with scikit learn?! In scikit learn i'm clustering things in this way
```
km... | The elbow criterion is a visual method. I have not yet seen a robust mathematical definition of it.
But k-means is a pretty crude heuristic, too.
So yes, you will need to run k-means with `k=1...kmax`, then *plot* the resulting SSQ and decide upon an "optimal" k.
There exist advanced versions of k-means such as X-mea... |
Whats the difference between a module and a library in Python? | 19,198,166 | 10 | 2013-10-05T13:08:25Z | 19,198,449 | 13 | 2013-10-05T13:40:24Z | [
"python"
] | I have background in Java and I am new to Python. I want to make sure I understand correctly Python terminology before I go ahead.
My understanding of a **module** is: a script which can be imported by many scripts, to make reading easier. Just like in java you have a class, and that class can be imported by many othe... | From [The Python Tutorial - Modules](http://docs.python.org/3/tutorial/modules.html)
* **Module**:
> A module is a file containing Python definitions and statements. The file name is the module name with the suffix `.py` appended.
* **Package**:
> Packages are a way of structuring Pythonâs module namespace by ... |
Sort a list of candidates according to a metric - Python? | 19,198,420 | 3 | 2013-10-05T13:37:19Z | 19,198,484 | 7 | 2013-10-05T13:45:49Z | [
"python",
"list",
"sorting"
] | I have a list of 2-D points
```
candidates = [(x1, y1), (x2, y2), (x3, y3), ...]
```
and a reference point `ref = (x0, y0)`.
I now wish to sort the list `candidates` according to their euclidean distances from the reference point `ref`, in ascending order.
What is **the most Pythonic way** of doing so? | Euclidean distance between two points `(x1, y1)` and `(x2, y2)` is given by:
```
sqrt((x1 - y1)^2 + (x2 - y2)^2))
```
To sort the list, you can use the formula, and also you can skip the `sqrt` part, as you are just doing comparison, and not calculating the actual distance. i.e:
```
if x > y then sqrt(x) > sqrt(y)
`... |
Using Counter() in Python to build histogram? | 19,198,920 | 12 | 2013-10-05T14:36:46Z | 19,199,002 | 24 | 2013-10-05T14:45:46Z | [
"python",
"histogram"
] | I saw on another question that I could use `Counter()` to count the number of occurrences in a set of strings. So if I have `['A','B','A','C','A','A']` I get `Counter({'A':3,'B':1,'C':1})`. But now, how can I use that information to build a histogram for example? | For your data it is probably better to use a barchart instead of a histogram. Check out this code:
```
from collections import Counter
import numpy as np
import matplotlib.pyplot as plt
labels, values = zip(*Counter(['A','B','A','C','A','A']).items())
indexes = np.arange(len(labels))
width = 1
plt.bar(indexes, val... |
Using Counter() in Python to build histogram? | 19,198,920 | 12 | 2013-10-05T14:36:46Z | 19,199,072 | 8 | 2013-10-05T14:54:16Z | [
"python",
"histogram"
] | I saw on another question that I could use `Counter()` to count the number of occurrences in a set of strings. So if I have `['A','B','A','C','A','A']` I get `Counter({'A':3,'B':1,'C':1})`. But now, how can I use that information to build a histogram for example? | You can write some really concise code to do this using [pandas](http://pandas.pydata.org/):
```
In [24]: import numpy as np
In [25]: from pandas import Series
In [27]: sample = np.random.choice(['a', 'b'], size=10)
In [28]: s = Series(sample)
In [29]: s
Out[29]:
0 a
1 b
2 b
3 b
4 a
5 b
6 b
7 ... |
python selenium webscraping "NoSuchElementException" not recognized | 19,200,497 | 12 | 2013-10-05T17:16:53Z | 19,200,889 | 41 | 2013-10-05T17:53:04Z | [
"python",
"exception",
"selenium",
"selenium-webdriver"
] | Sometimes on a page I'll be looking for an element which may or may not be there. I wanted to try/catch this case with a `NoSuchElementException`, which selenium was throwing when certain HTML elements didn't exist. Original exception:
```
NoSuchElementException: Message: u'Unable to locate element: {"method":"css sel... | Try either `elt.NoSuchElementException` or `driver.NoSuchElementException` as it is probably defined in the scope of one of them. Alternatively you may have to use `from selenium import NoSuchElementException` to bring it into scope.
Better yet: `from selenium.common.exceptions import NoSuchElementException` |
how to delete json object using python? | 19,201,233 | 5 | 2013-10-05T18:28:21Z | 19,202,737 | 10 | 2013-10-05T21:07:01Z | [
"python",
"json"
] | I am using python to delete and update a JSON file generated from the data provided by user, so that only few items should be stored in the database. I want to delete a particular object from the JSON file.
My JSON file is:
```
[
{
"ename": "mark",
"url": "Lennon.com"
},
{
"ename": "egg",
... | Here's a complete example that loads the JSON file, removes the target object, and then outputs the updated JSON object to file.
```
#!/usr/bin/python
# Load the JSON module and use it to load your JSON file.
# I'm assuming that the... |
How to save a dictionary to a file in Python? | 19,201,290 | 14 | 2013-10-05T18:34:23Z | 19,201,448 | 47 | 2013-10-05T18:50:51Z | [
"python",
"file",
"dictionary",
"python-3.x"
] | I have problem with changing a dict value and saving the dict to a text file (the format must be same), I only want to change the `member_phone` field.
My text file is the following format:
```
memberID:member_name:member_email:member_phone
```
and I split the text file with:
```
mdict={}
for line in file:
x=li... | Python has the [pickle](http://docs.python.org/2/library/pickle.html) module just for this kind of thing.
These functions are all that you need for saving and loading almost any object:
```
def save_obj(obj, name ):
with open('obj/'+ name + '.pkl', 'wb') as f:
pickle.dump(obj, f, pickle.HIGHEST_PROTOCOL)
... |
How to save a dictionary to a file in Python? | 19,201,290 | 14 | 2013-10-05T18:34:23Z | 32,216,025 | 11 | 2015-08-26T00:05:53Z | [
"python",
"file",
"dictionary",
"python-3.x"
] | I have problem with changing a dict value and saving the dict to a text file (the format must be same), I only want to change the `member_phone` field.
My text file is the following format:
```
memberID:member_name:member_email:member_phone
```
and I split the text file with:
```
mdict={}
for line in file:
x=li... | Pickle is probably the best option, but in case anyone wonders how to save and load a dictionary to a file using NumPy:
```
import numpy as np
# Save
dictionary = {'hello':'world'}
np.save('my_file.npy', dictionary)
# Load
read_dictionary = np.load('my_file.npy').item()
print(read_dictionary['hello']) # displays "w... |
How to select columns from groupby object in pandas? | 19,202,093 | 3 | 2013-10-05T19:58:29Z | 19,202,149 | 7 | 2013-10-05T20:03:57Z | [
"python",
"pandas"
] | I grouped my dataframe by the two columns below
```
df = pandas.DataFrame({"a":[1,1,3], "b":[4,5.5,6], "c":[7,8,9], "name":["hello","hello","foo"]})
df.groupby(["a", "name"]).median()
```
and the result is:
```
b c
a name
1 hello 4.75 7.5
3 foo 6.00 9.0
```
How can I access the `nam... | You need to get the index values, they are not columns. In this case level 1
```
df.groupby(["a", "name"]).median().index.get_level_values(1)
Out[2]:
Index([u'hello', u'foo'], dtype=object)
```
You can also pass the index name
```
df.groupby(["a", "name"]).median().index.get_level_values('name')
```
as this will ... |
In Python, how to write a string to a file on a remote machine? | 19,202,314 | 6 | 2013-10-05T20:21:02Z | 19,202,764 | 7 | 2013-10-05T21:10:12Z | [
"python",
"file",
"ssh",
"network-programming",
"rsync"
] | On Machine1, I have a Python2.7 script that computes a big (up to 10MB) binary string in RAM that I'd like to write to a disk file on Machine2, which is a remote machine. What is the best way to do this?
Constraints:
* Both machines are Ubuntu 13.04. The connection between them is fast -- they are on the same network... | [Paramiko](http://docs.paramiko.org/) supports opening files on remote machines:
```
import paramiko
def put_file(machinename, username, dirname, filename, data):
ssh = paramiko.SSHClient()
ssh.set_missing_host_key_policy(paramiko.AutoAddPolicy())
ssh.connect(machinename, username=username)
sftp = ssh... |
How to have one thread listen for data while main thread is doing some operation | 19,202,362 | 2 | 2013-10-05T20:25:20Z | 19,202,519 | 7 | 2013-10-05T20:42:18Z | [
"python",
"multithreading"
] | I am trying to create a one thread to listen for incoming data from COM serial port while main thread is doing some operation.
Here is my code (some codes are omitted for brevity) :
```
def readMsg( serial ):
msgArray = []
while ( True ):
char = "0x" + serial.read().encode('hex')
if char == '0... | I can't test this for you, but think carefully about this line:
```
readMsgThread = threading.Thread( target=readMsg(serialPort) )
```
That **calls** `readMsg(serialPort)` at the time the assignment is excecuted, and passes the result as `target`. I'm guessing you almost certainly want to do:
```
readMsgThread = thr... |
Exclude fields in Django admin for users other than superuser | 19,203,067 | 9 | 2013-10-05T21:45:13Z | 19,206,883 | 11 | 2013-10-06T08:27:01Z | [
"python",
"django"
] | I have a simple `MyUser` class with `PermissionsMixin`. `user.is_superuser` equals `True` only for superusers. I'd like to be able to do something similar to this in my `admin.py`:
```
if request.user.is_superuser:
fieldsets = (
(None, {'fields': ('email', 'password')}),
('Permissio... | If I understand you correctly, what you want to do is override the get\_form method for the ModelAdmin. Base on [the example from django documentation](https://docs.djangoproject.com/en/dev/ref/contrib/admin/), it would look something like this:
```
class MyUserAdmin(admin.ModelAdmin):
def get_form(self, request, ... |
Exclude fields in Django admin for users other than superuser | 19,203,067 | 9 | 2013-10-05T21:45:13Z | 25,026,806 | 14 | 2014-07-30T00:01:17Z | [
"python",
"django"
] | I have a simple `MyUser` class with `PermissionsMixin`. `user.is_superuser` equals `True` only for superusers. I'd like to be able to do something similar to this in my `admin.py`:
```
if request.user.is_superuser:
fieldsets = (
(None, {'fields': ('email', 'password')}),
('Permissio... | Accepted answer is close but as others point out, get\_form is called multiple times on the same instance of the Admin model and the instance is reused, so you can end up with fields repeated or other users seeing the fields after self.fields is modified. Try this out in Django <=1.6:
```
class MyAdmin(admin.ModelAdmi... |
Mocking urllib2.urlopen().read() for different responses | 19,203,627 | 3 | 2013-10-05T23:04:00Z | 19,204,230 | 8 | 2013-10-06T00:45:30Z | [
"python",
"unit-testing",
"mocking"
] | I am trying to mock the urllib2.urlopen library in a way that I should get different responses for different urls I pass into the function.
The way I am doing it in my test file now is like this
```
@patch(othermodule.urllib2.urlopen)
def mytest(self, mock_of_urllib2_urllopen):
a = Mock()
a.read.side_effect =... | The argument to `patch` needs to be a description of the *location* of the object, not the object *itself*. So your problem looks like it may just be that you need to stringify your argument to `patch`.
Just for completeness, though, here's a fully working example. First, our module under test:
```
# mod_a.py
import ... |
Flask-SQLAlchemy - model has no attribute 'foreign_keys' | 19,205,290 | 6 | 2013-10-06T04:03:11Z | 19,261,449 | 13 | 2013-10-09T01:27:35Z | [
"python",
"sqlalchemy",
"flask",
"flask-sqlalchemy"
] | I have 3 models created with Flask-SQLalchemy: User, Role, UserRole
user.py:
```
class Role( ActiveRecord, db.Model ):
__tablename__ = "roles"
# Schema
id = db.Column( db.Integer, primary_key = True )
name = db.Column( db.String( 24 ), unique = True )
description = db.Column( db.String( 90 ) )... | it's a little tough here because you are using some unknown base classes like "ActiveRecord" and such. However, it looks pretty much like that "secondary" argument is wrong:
```
class User( db.Model, ActiveRecord ):
__tablename__ = "users"
# Schema
id = db.Column( db.Integer, primary_key = True )
e... |
How to call Base Class's __init__ method from the child class? | 19,205,916 | 30 | 2013-10-06T06:01:06Z | 19,205,946 | 36 | 2013-10-06T06:06:47Z | [
"python",
"python-2.7",
"inheritance",
"constructor"
] | If I have a python class as:
```
class BaseClass(object):
#code and the init function of the base class
```
And then I define a child class such as:
```
class ChildClass(BaseClass):
#here I want to call the init function of the base class
```
If the init function of the base class takes some arguments that I am tak... | You could use `super(ChildClass, self).__init__()`
```
class BaseClass(object):
def __init__(self, *args, **kwargs):
pass
class ChildClass(BaseClass):
def __init__(self, *args, **kwargs):
super(ChildClass, self).__init__(*args, **kwargs)
```
Your indentation is incorrect, here's the modified ... |
How to call Base Class's __init__ method from the child class? | 19,205,916 | 30 | 2013-10-06T06:01:06Z | 27,740,540 | 10 | 2015-01-02T10:17:45Z | [
"python",
"python-2.7",
"inheritance",
"constructor"
] | If I have a python class as:
```
class BaseClass(object):
#code and the init function of the base class
```
And then I define a child class such as:
```
class ChildClass(BaseClass):
#here I want to call the init function of the base class
```
If the init function of the base class takes some arguments that I am tak... | As Mingyu pointed out, there is a problem in formatting. Other than that, I would strongly recommend **not using the Derived class's name** while calling `super()` since it makes your code inflexible (code maintenance and inheritance issues). In Python 3, Use `super().__init__` instead. Here is the code after incorpora... |
Gaussian fit for Python | 19,206,332 | 9 | 2013-10-06T07:08:25Z | 19,207,683 | 11 | 2013-10-06T10:13:16Z | [
"python",
"gaussian"
] | I'm trying to fit a Gaussian for my data (which is already a rough gaussian). I've already taken the advice of those here and tried `curve_fit` and `leastsq` but I think that I'm missing something more fundamental (in that I have no idea how to use the command).
Here's a look at the script I have so far
```
import pyl... | **Here is corrected code:**
```
import pylab as plb
import matplotlib.pyplot as plt
from scipy.optimize import curve_fit
from scipy import asarray as ar,exp
x = ar(range(10))
y = ar([0,1,2,3,4,5,4,3,2,1])
n = len(x) #the number of data
mean = sum(x*y)/n #note this correctio... |
Interacting with program after execution | 19,207,019 | 6 | 2013-10-06T08:44:30Z | 27,978,591 | 15 | 2015-01-16T06:43:33Z | [
"python",
"windows",
"ide",
"pycharm"
] | In PyCharm, after I run a script it automatically kills it:
> C:\Users\Sean.virtualenvs\Stanley\Scripts\python.exe C:/Users/Sean/PycharmProjects/Stanley/Stanley.py
>
> Process finished with exit code 0
How can I interact with the script after it starts? For lack of a better way to phrase it, how can I get the
> >>>
... | in Pycharm, Run/Debug menu choose Edit Configuration, check the box before 'Show command line afterwards' |
Trying to append a list in its own list... what happens? | 19,207,020 | 2 | 2013-10-06T08:44:30Z | 19,207,042 | 9 | 2013-10-06T08:47:02Z | [
"python",
"list",
"python-3.x"
] | ```
list1 = ['inception', 'dream', 'movie']
list2 = list1
list1.append(list2)
list1
```
If I run this code on the terminal,
```
['inception', 'dream', 'movie',[...]]
```
is the output. What happens if I append a list in its own list? | List elements are just references to other Python values. You've stored a reference to the list itself inside the list.
The list representation reflects this; instead of throwing an error or filling your terminal with endlessly nested representations of the same list, Python shows `[...]` to indicate a recursive struc... |
If and Inline if, what are the advantages and disadvantages? | 19,207,722 | 2 | 2013-10-06T10:18:36Z | 19,207,743 | 7 | 2013-10-06T10:20:48Z | [
"python",
"if-statement",
"inline-if"
] | I'm a little curious about the difference between if and inline if, in Python. Which one is better?
Is there any reason to use *inline if*, other than the fact that it's shorter?
Also, is there anything wrong with this statement? I'm getting a syntax error: `SyntaxError: can't assign to conditional expression`
```
a... | The advantage of the inline `if` expression is that it's an expression, which means you can use it inside other expressionsâlist comprehensions, lambda functions, etc.
The disadvantage of the inline `if` expression is *also* that it's an expression, which means you can't use any statements inside of it.
---
A perf... |
Byte Array to Hex String | 19,210,414 | 17 | 2013-10-06T15:22:09Z | 19,210,442 | 35 | 2013-10-06T15:24:48Z | [
"python",
"string",
"python-2.7",
"bytearray"
] | I have data stored in a byte array. How can I convert this data into a hex string?
Example of my byte array:
```
array_alpha = [ 133, 53, 234, 241 ]
``` | Using [`str.format`](http://docs.python.org/2/library/stdtypes#str.format):
```
>>> array_alpha = [ 133, 53, 234, 241 ]
>>> print ''.join('{:02x}'.format(x) for x in array_alpha)
8535eaf1
```
or using [`format`](http://docs.python.org/2/library/functions.html#format)
```
>>> print ''.join(format(x, '02x') for x in a... |
How to get virtualenv to use dist-packages on Ubuntu? | 19,210,964 | 11 | 2013-10-06T16:12:13Z | 19,211,566 | 11 | 2013-10-06T17:13:39Z | [
"python",
"ubuntu",
"virtualenv",
"packages",
"environment"
] | I know that virtualenv, if not passed the `--no-site-packages` argument when creating a new virtual environment, will link the packages in `/usr/local/lib/python2.7/site-packages` (for Python 2.7) with a newly-created virtual environment. On Ubuntu 12.04 LTS, I have three locations where Python 2.7 packages can be inst... | This might be a legitimate use of `PYTHONPATH` - an environmental variable that `virtualenv` doesn't touch, which uses the same syntax as the environmental variable `PATH`, in bash `PYTHONPATH=/usr/lib/python2.7/dist-packages:/usr/local/lib/python2.7/dist-packages` in a .bashrc or similar. If you followed this path,
1... |
Change default return value of a defaultdict *after* initialization | 19,211,194 | 5 | 2013-10-06T16:35:46Z | 19,211,216 | 8 | 2013-10-06T16:38:03Z | [
"python",
"collections",
"defaultdict"
] | Is there a way to change the default\_factory of a defaultdict (the value which is returned when a non-existent key is called) after it has been created?
For example, when a defaultdict such as
```
d = defaultdict(lambda:1)
```
is created, `d` would return 1 whenever a non-existent key such as `d['absent']` is calle... | Assign the new value to the `default_factory` attribute of defaultdict.
[default\_factory](http://docs.python.org/2/library/collections.html#collections.defaultdict.default_factory):
> This attribute is used by the `__missing__()` method;
> it is initialized from the first argument to the constructor, if
> present, o... |
PySide: Segfault(?) when using QItemSelectionModel with QListView | 19,211,430 | 8 | 2013-10-06T16:58:47Z | 21,197,671 | 13 | 2014-01-17T23:08:43Z | [
"python",
"qt",
"crash",
"segmentation-fault",
"pyside"
] | Same exact problem as this: [Connecting QTableView selectionChanged signal produces segfault with PyQt](http://stackoverflow.com/questions/14803315/connecting-qtableview-selectionchanged-signal-produces-segfault-with-pyqt)
I have a QListView, and I want to call a function when an item is selected:
```
self.server_lis... | Try holding a reference to the selection model for the lifetime of the selection model. That worked for me with a similar problem (seg fault when connecting to currentChanged event on a table views selection model).
```
self.server_list = QtGui.QListView(self.main_widget)
self.server_list_model = QtGui.QStandardItemMo... |
Plotting a histogram from pre-counted data in Matplotlib | 19,212,508 | 13 | 2013-10-06T18:41:51Z | 19,212,682 | 9 | 2013-10-06T18:58:34Z | [
"python",
"matplotlib",
"histogram"
] | I'd like to use Matplotlib to plot a histogram over data that's been pre-counted. For example, say I have the raw data
`data = [1, 2, 2, 3, 4, 5, 5, 5, 5, 6, 10]`
Given this data, I can use
`pylab.hist(data, bins=[...])`
to plot a histogram.
In my case, the data has been pre-counted and is represented as a diction... | You can use the `weights` keyword argument to `np.histgram` (which `plt.hist` calls underneath)
```
val, weight = zip(*[(k, v) for k,v in counted_data.items()])
plt.hist(val, weights=weight)
```
Assuming you *only* have integers as the keys, you can also use `bar` directly:
```
min_bin = np.min(counted_data.keys())
... |
Plotting a histogram from pre-counted data in Matplotlib | 19,212,508 | 13 | 2013-10-06T18:41:51Z | 19,214,693 | 7 | 2013-10-06T22:26:09Z | [
"python",
"matplotlib",
"histogram"
] | I'd like to use Matplotlib to plot a histogram over data that's been pre-counted. For example, say I have the raw data
`data = [1, 2, 2, 3, 4, 5, 5, 5, 5, 6, 10]`
Given this data, I can use
`pylab.hist(data, bins=[...])`
to plot a histogram.
In my case, the data has been pre-counted and is represented as a diction... | I used [pyplot.hist](http://matplotlib.org/1.3.0/api/pyplot_api.html#matplotlib.pyplot.hist)'s `weights` option to weight each key by its value, producing the histogram that I wanted:
`pylab.hist(counted_data.keys(), weights=counted_data.values(), bins=range(50))`
This allows me to rely on `hist` to re-bin my data. |
Draw graph in NetworkX | 19,212,979 | 5 | 2013-10-06T19:27:56Z | 19,213,049 | 8 | 2013-10-06T19:35:03Z | [
"python",
"matplotlib",
"ipython",
"ipython-notebook",
"networkx"
] | I'm trying to draw any graph in NetworkX, but get nothing, not even errors:
```
import networkx as nx
import matplotlib.pyplot as plt
g1=nx.petersen_graph()
nx.draw(g1)
``` | Add to the end:
```
plt.show()
```
---
```
import networkx as nx
import matplotlib.pyplot as plt
g1 = nx.petersen_graph()
nx.draw(g1)
plt.show()
```
When run from an interactive shell where `plt.ion()` has been called, the `plt.show()` is not needed. This is probably why it is omitted in a lot of examples.
If you ... |
How to html input to Flask? | 19,213,226 | 4 | 2013-10-06T19:52:35Z | 19,213,353 | 10 | 2013-10-06T20:03:43Z | [
"python",
"html",
"http",
"website",
"flask"
] | I have this html bit:
```
<form action='quiz_answers'>
<p> Question1? </p>
<input type="radio" name="q1" value="2">Answer1</input>
<input type="radio" name="q1" value="1">Answer2</input>
<input type="radio" name="q1" value="0">Answer3</input>
<input type="radio" name="q1" value="0">Answer4</input>
... | You should be able to add a `submit` button to the form to POST or GET the data response back to the `action`.
In this case, you will probably want to modify your form tag definition to:
```
<form action="/quiz_answers" method="POST">
```
And add a submit button like this:
```
<input type="submit" value="Submit!" /... |
Using "and" and "or" operator with Python strings | 19,213,535 | 9 | 2013-10-06T20:22:19Z | 19,213,583 | 9 | 2013-10-06T20:27:42Z | [
"python",
"string",
"boolean-operations"
] | I don't understand the meaning of the line:
```
parameter and (" " + parameter) or ""
```
where **parameter** is string
Why would one want to use `and` and `or` operator, in general, with python strings? | Suppose you are using the value of `parameter`, but if the value is say `None`, then you would rather like to have an empty string `""` instead of `None`. What would you do in general?
```
if parameter:
# use parameter (well your expression using `" " + parameter` in this case
else:
# use ""
```
This is what ... |
How do you plot a vertical line on a time series plot in Pandas? | 19,213,789 | 31 | 2013-10-06T20:48:04Z | 19,213,836 | 56 | 2013-10-06T20:54:47Z | [
"python",
"matplotlib",
"plot",
"pandas"
] | How do you plot a vertical line (vlines) in a Pandas series plot? I am using Pandas to plot rolling means, etc and would like to mark important positions with a vertical line. Is it possible to use vlines or something similar to accomplish this? If so, could someone please provide an example? In this case, the x axis i... | ```
plt.axvline(x_position)
```
It takes the standard plot formatting options (`linestlye`, `color`, ect)
[(doc)](http://matplotlib.org/api/pyplot_api.html)
If you have a reference to your `axes` object:
```
ax.axvline(x, color='k', linestyle='--')
``` |
How can I efficiently move from a Pandas dataframe to JSON | 19,214,588 | 10 | 2013-10-06T22:12:55Z | 19,214,708 | 17 | 2013-10-06T22:27:43Z | [
"javascript",
"python",
"json",
"d3.js",
"pandas"
] | I've started using `pandas` to do some aggregation by date. My goal is to count all of the instances of a measurement that occur on a particular day, and to then represent this in `D3`. To illustrate my workflow, I have a queryset (from `Django`) that looks like this:
```
queryset = [{'created':"05-16-13", 'counter':1... | Transform your date index back into a simple data column with `reset_index`, and then generate your json object by using the `orient='index'` property:
```
In [11]: aggregated_df.reset_index().to_json(orient='index')
Out[11]: '{"0":{"created":"05-16-13","counter":3},"1":{"created":"05-17-13","counter":1},"2":{"created... |
More elegant/Pythonic way of printing elements of tuple? | 19,215,100 | 2 | 2013-10-06T23:20:26Z | 19,215,102 | 8 | 2013-10-06T23:21:27Z | [
"python",
"python-2.7"
] | I have a function which returns a large set of integer values as a tuple. For example:
```
def solution():
return 1, 2, 3, 4 #etc.
```
I want to elegantly print the solution without the tuple representation. (i.e. parentheses around the numbers).
I tried the following two pieces of code.
```
print ' '.join(map(... | `print(*solution())` actually *can be* valid on python 2.7, just put:
```
from __future__ import print_function
```
On the top of your file.
You could also iterate through the tuple:
```
for i in solution():
print i,
```
This is equivalent to:
```
for i in solution():
print(i, end= ' ')
```
If you ever u... |
2.2GB JSON file parses inconsistently | 19,215,847 | 6 | 2013-10-07T01:23:32Z | 19,216,246 | 9 | 2013-10-07T02:27:05Z | [
"python",
"json",
"unicode",
"utf-8"
] | I am trying to decode a large utf-8 json file (2.2 GB). I load the file like so:
```
f = codecs.open('output.json', encoding='utf-8')
data = f.read()
```
If I try to do any of: `json.load`, `json.loads` or `json.JSONDecoder().raw_decode` I get the error:
```
----------------------------------------------------------... | I'd add this as a comment, but the formatting capabilities in comments are too limited.
Staring at the source code,
```
raise ValueError(errmsg("Extra data", s, end, len(s)))
```
calls this function:
```
def errmsg(msg, doc, pos, end=None):
...
fmt = '{0}: line {1} column {2} - line {3} column {4} (char {5}... |
Python: give start and end of week data from a given date | 19,216,334 | 19 | 2013-10-07T02:43:13Z | 19,216,386 | 38 | 2013-10-07T02:49:32Z | [
"python",
"date",
"time"
] | ```
day = "13/Oct/2013"
print("Parsing :",day)
day, mon, yr= day.split("/")
sday = yr+" "+day+" "+mon
myday = time.strptime(sday, '%Y %d %b')
Sstart = yr+" "+time.strftime("%U",myday )+" 0"
Send = yr+" "+time.strftime("%U",myday )+" 6"
startweek = time.strptime(Sstart, '%Y %U %w')
endweek = time.strptime(Send, '%Y %U %... | Use the `datetime` module.
This will yield start and end of week (from Monday to Sunday):
```
from datetime import datetime, timedelta
day = '12/Oct/2013'
dt = datetime.strptime(day, '%d/%b/%Y')
start = dt - timedelta(days=dt.weekday())
end = start + timedelta(days=6)
print(start)
print(end)
```
EDIT:
```
print(st... |
Why simple factorial algorithms in JS are much faster than in Python or R? | 19,217,073 | 4 | 2013-10-07T04:27:56Z | 19,217,169 | 8 | 2013-10-07T04:38:24Z | [
"javascript",
"python",
"node.js"
] | Why is JavaScript being so much more faster in this computation?
I've been making some tests with four simple factorial algorithms: recursion, tail recursion, `while` loop and `for` loop. I've made the tests in R, Python, and Javascript.
I measured the time it took for each algorithm to compute 150 factorial, 5000 ti... | I believe that the main difference is that Python have [bignums](http://en.wikipedia.org/wiki/Arbitrary-precision_arithmetic) while Javascript does not (it uses double IEEE754 floating point).
So your program don't compute the same things. With Python, they compute all the digits of factorial, with JS only a crude flo... |
Why simple factorial algorithms in JS are much faster than in Python or R? | 19,217,073 | 4 | 2013-10-07T04:27:56Z | 19,223,124 | 14 | 2013-10-07T11:02:51Z | [
"javascript",
"python",
"node.js"
] | Why is JavaScript being so much more faster in this computation?
I've been making some tests with four simple factorial algorithms: recursion, tail recursion, `while` loop and `for` loop. I've made the tests in R, Python, and Javascript.
I measured the time it took for each algorithm to compute 150 factorial, 5000 ti... | In detail I can only speak for R, but here are my 2ct. Maybe you can analyze what happens in the other languages and then come to conclusions.
First of all, however, your R version of `factorialRecursive` is not recursive: you call R's `factorial (n - 1)` which uses the $\Gamma$ function.
Here are my benchmarking res... |
pycharm remote project with virtualenv | 19,218,011 | 10 | 2013-10-07T06:02:36Z | 20,163,768 | 15 | 2013-11-23T14:50:01Z | [
"python",
"django",
"virtualenv",
"pycharm"
] | I have the remote server with a few virtualenv environments (django projects).
How can I open, develop and debug these projects completely remote?
Shall I mount remote directory via sshfs to open a project?
(I can't open project other way than as local path)
I am working on debian and windows xp. | I've found the decision and asked the support which confirmed its:
Here is the steps:
1. copy a project to a local directory.
2. configure: tools - deployment, to upload this local copy to remote server
3. make deployment automatic: tools - deployment - "automatic upload"
4. add remote interpreter: file - settings - ... |
Python: First In First Out Print | 19,219,903 | 2 | 2013-10-07T08:14:34Z | 19,220,065 | 11 | 2013-10-07T08:24:43Z | [
"python",
"lifo"
] | I'm a beginner in python and I'm having an issue with this program:
The program below is a Last In First Out (LIFO). I want to make it First in First Out (FIFO) Program.
```
from NodeList import Node
class QueueLL:
def __init__(self):
self.head = None
def enqueueQLL(self,item):
temp = Node... | Apart from learning purposes I would not advise using a custom data structure for making a LIFO or FIFO. The built in data-type `list` is just fine after all.
You can add items using the `append` method and remove them using `pop`. For a LIFO this would look like this:
```
stack = list()
stack.append(1)
stack.append(... |
How to print terminal formatted output to a variable | 19,223,108 | 5 | 2013-10-07T11:02:07Z | 19,223,797 | 7 | 2013-10-07T11:34:00Z | [
"python"
] | Is there a method to print terminal formatted output to a variable?
```
print 'a\bb'
--> 'b'
```
I want that string 'b' to a variable - so how to do it?
I am working with a text string from telnet. Thus I want to work with the string that would be printed to screen.
So what I am looking for is something like this:
... | This turns out to be quite tricky because there are a *lot* of terminal formatting commands (including e.g. cursor up/down/left/right commands, terminal colour codes, vertical and horizontal tabs, etc.).
So, if you want to emulate a terminal properly, get a terminal emulator! [`pyte`](https://github.com/selectel/pyte)... |
'module' object has no attribute 'GeoSQLCompiler' | 19,226,025 | 5 | 2013-10-07T13:21:01Z | 19,631,325 | 18 | 2013-10-28T09:37:36Z | [
"python",
"django",
"geodjango"
] | I am new to geodjango. I am using django-1.4.5 and my database settings,
```
DATABASES = {
"default": {
"ENGINE": "django.db.backends.postgresql_psycopg2", # Add "postgresql_psycopg2", "postgresql", "mysql", "sqlite3" or "oracle".
"NAME": "mydb", # Or path to database file if ... | Replace:
```
'ENGINE': 'django.db.backends.postgresql_psycopg2'
```
with
```
'ENGINE': 'django.contrib.gis.db.backends.postgis'
``` |
Python PANDAS, change one value based on another value | 19,226,488 | 7 | 2013-10-07T13:42:28Z | 19,226,617 | 17 | 2013-10-07T13:48:43Z | [
"python",
"pandas"
] | I'm trying to reprogram my Stata code into Python for speed improvements, and I was pointed in the direction of PANDAS. I am, however, having a hard time wrapping my head around how to process the data.
Let's say I want to iterate over all values in the column head 'ID.' If that ID matches a specific number, then I wa... | One option is to use Python's slicing and indexing features to logically evaluate the places where your condition holds and overwrite the data there.
Assuming you can load your data directly into `pandas` with `pandas.read_csv` then the following code might be helpful for you.
```
import pandas
df = pandas.read_csv("... |
Count Repeated occurence of a substring in string | 19,226,975 | 4 | 2013-10-07T14:05:22Z | 19,227,173 | 14 | 2013-10-07T14:15:13Z | [
"python",
"regex",
"string",
"count"
] | Suppose I have a string like this
```
aa = 'booked#booked#available#available#available#available#available#booked#available#booked'
```
Now I want to find out that `'available'` substring has occur in this string how many times repeatedly. So in this case it should be 5 as `'available' is coming 5 times repeatedly,i... | [Groupby](http://docs.python.org/2/library/itertools.html#itertools.groupby) from itertools is splendid for these types of problems:
```
from itertools import groupby
aa = 'booked#booked#available#available#available#available#available#booked#available#booked'
words = aa.split('#')
for key, group in groupby(words):
... |
Check if a function uses @classmethod | 19,227,724 | 8 | 2013-10-07T14:40:55Z | 19,228,282 | 12 | 2013-10-07T15:05:28Z | [
"python",
"decorator",
"class-method",
"python-decorators"
] | **TL;DR** How do I find out whether a function was defined using `@classmethod` or something with the same effect?
---
**My problem**
For implementing a class decorator I would like to check if a method takes the class as its first argument, for example as achieved via
```
@classmethod
def function(cls, ...):
```
... | For Python 2, you need to test both if the object is a method, *and* if `__self__` points to the class (for regular methods it'll be `None` when retrieved from the class):
```
>>> class Foo(object):
... @classmethod
... def bar(cls):
... pass
... def baz(self):
... pass
...
>>> Foo.baz
<un... |
AWK doesn't work on first row delimited by ^A | 19,227,926 | 2 | 2013-10-07T14:49:04Z | 19,228,052 | 9 | 2013-10-07T14:54:45Z | [
"python",
"bash",
"awk"
] | I have a file looks similar like this(^A is non printing character and below is the view in VI), columns delimited by ^A and rows terminated by \n.
```
# input
2013-10-07 10:40:14.170976^Awww.abc.com/0
2013-10-07 10:40:14.171074^Awww.abc.com/1
2013-10-07 10:40:14.171101^Awww.abc.com/2
2013-10-07 10:40:14.171133^Awww.a... | It's because those variables have to be set before beginning to process input files, in a `BEGIN` block, like:
```
awk 'BEGIN { FS="\x01" } {print $1}' input
``` |
Efficient way of counting True and False | 19,228,979 | 6 | 2013-10-07T15:41:44Z | 19,229,096 | 18 | 2013-10-07T15:47:39Z | [
"python",
"algorithm",
"python-2.7",
"counting"
] | This may be a trivial problem, but I want to learn more about other more clever and efficient ways of solving it.
I have a list of items and each item has a property `a` whose value is binary.
* If every item in the list has `a == 0`, then I set a separate variable `b = 0`.
* If every item in the list has `a == 1`, t... | I would suggest using `any` and `all`. I would say that the benefit of this is readability rather than cleverness or efficiency. For example:
```
>>> vals0 = [0, 0, 0, 0, 0]
>>> vals1 = [1, 1, 1, 1, 1]
>>> vals2 = [0, 1, 0, 1, 0]
>>> def category(vals):
... if all(vals):
... return 1
... elif any(vals)... |
Efficient way of counting True and False | 19,228,979 | 6 | 2013-10-07T15:41:44Z | 19,229,421 | 26 | 2013-10-07T16:01:28Z | [
"python",
"algorithm",
"python-2.7",
"counting"
] | This may be a trivial problem, but I want to learn more about other more clever and efficient ways of solving it.
I have a list of items and each item has a property `a` whose value is binary.
* If every item in the list has `a == 0`, then I set a separate variable `b = 0`.
* If every item in the list has `a == 1`, t... | One pass through the list, and no extra data structures constructed:
```
def zot(bs):
n, s = len(bs), sum(bs)
return 1 if n == s else 2 if s else 0
``` |
Efficient way of counting True and False | 19,228,979 | 6 | 2013-10-07T15:41:44Z | 19,230,091 | 15 | 2013-10-07T16:35:53Z | [
"python",
"algorithm",
"python-2.7",
"counting"
] | This may be a trivial problem, but I want to learn more about other more clever and efficient ways of solving it.
I have a list of items and each item has a property `a` whose value is binary.
* If every item in the list has `a == 0`, then I set a separate variable `b = 0`.
* If every item in the list has `a == 1`, t... | Somebody mentioned code golf, so can't resist a variation on @senderle's:
```
[0,2,1][all(vals) + any(vals)]
```
*Short explanation*: This uses the boolean values as their integer equivalents to index a list of desired responses. If `all` is true then `any` must also be true, so their sum is `2`. `any` by itself give... |
Python / Django multi-tenancy solution | 19,230,734 | 7 | 2013-10-07T17:10:12Z | 19,230,828 | 9 | 2013-10-07T17:15:41Z | [
"python",
"django",
"multi-tenant"
] | I could use some help creating a plan of attack for a project I'm working on.
Imagine that the site is for a group that oversees regional sales offices, distributed around the world. The purpose of this project is to let superusers spin up a new sub-site specific to each and every office, at a fast pace -- sites are a... | There is a great app called [django-tenant-schemas](https://github.com/bcarneiro/django-tenant-schemas) that uses PostgreSQL schemas mechanism to create multi-tenancy.
What you get is specyfing `SHARED_APPS` that contain objects shared across all the schemas (sub-sites), and `TENANT_APPS` that contain objects specific... |
Image.open() cannot identify image file - Python? | 19,230,991 | 12 | 2013-10-07T17:24:53Z | 20,863,145 | 45 | 2013-12-31T21:02:15Z | [
"python",
"python-imaging-library"
] | I am running Python 2.7 in Visual Studio 2013. The code previously worked ok when in Spyder, but when I run:
```
import numpy as np
import scipy as sp
import math as mt
import matplotlib.pyplot as plt
import Image
import random
# (0, 1) is N
SCALE = 2.2666 # the scale is chosen to be 1 m = 2.266666666 pixels
MIN_LENG... | I had a same issue.
```
from PIL import Image
```
instead of
```
import Image
```
fixed the issue |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.