
M2-Encoder: Advancing Bilingual Image-Text Understanding by Large-scale Efficient Pretraining
Paper • 2401.15896 • Published
M2-Encoder-1B is a Hugging Face export of the bilingual vision-language foundation model from the paper M2-Encoder: Advancing Bilingual Image-Text Understanding by Large-scale Efficient Pretraining.
It supports Chinese-English image-text retrieval, zero-shot image classification, transformers remote-code loading, ONNXRuntime inference, and Hugging Face Inference Endpoints via the bundled handler.py.
This is the larger M2-Encoder variant with a wider backbone and 1024-dimensional embeddings, intended for better retrieval and zero-shot classification quality.
M2Cognition/M2_Encoder_Largemalusama/M2-Encoder-1B| Item | Value |
|---|---|
| Variant | M2-Encoder-1B |
| Languages | Chinese, English |
| Embedding dimension | 1024 |
| Image size | 224 |
| Main tasks | Image-text retrieval, zero-shot image classification, bilingual feature extraction |
| Weight format | safetensors |
| ONNX export | onnx/text_encoder.onnx, onnx/image_encoder.onnx |
m2_encoder_1B.safetensors: main transformers weight fileonnx/text_encoder.onnx: text embedding encoderonnx/image_encoder.onnx: image embedding encoderexamples/run_onnx_inference.py: runnable ONNX examplehandler.py: custom handler for Hugging Face Inference EndpointsThe original ModelScope sample computes probabilities from raw normalized embedding dot products:
from transformers import AutoModel, AutoProcessor
repo_id = "malusama/M2-Encoder-1B"
model = AutoModel.from_pretrained(repo_id, trust_remote_code=True)
processor = AutoProcessor.from_pretrained(repo_id, trust_remote_code=True)
text_inputs = processor(
text=["杰尼龟", "妙蛙种子", "小火龙", "皮卡丘"],
return_tensors="pt",
)
image_inputs = processor(images="pokemon.jpeg", return_tensors="pt")
text_outputs = model(**text_inputs)
image_outputs = model(**image_inputs)
probs = (image_outputs.image_embeds @ text_outputs.text_embeds.t()).softmax(dim=-1)
print(probs)
model(**inputs) also returns logits_per_image and logits_per_text, which use the model's learned logit_scale.
Those logits are useful, but they are not the same computation as the raw dot product used in the original ModelScope demo.
This repo also includes two ONNX exports:
onnx/text_encoder.onnxonnx/image_encoder.onnxMinimal example:
import importlib
import json
import os
import sys
import onnxruntime as ort
from huggingface_hub import snapshot_download
from PIL import Image
repo_id = "malusama/M2-Encoder-1B"
model_dir = snapshot_download(repo_id=repo_id)
sys.path.insert(0, model_dir)
tokenizer_config = json.load(open(os.path.join(model_dir, "tokenizer_config.json"), "r", encoding="utf-8"))
GLMChineseTokenizer = importlib.import_module("tokenization_glm").GLMChineseTokenizer
M2EncoderImageProcessor = importlib.import_module("image_processing_m2_encoder").M2EncoderImageProcessor
tokenizer = GLMChineseTokenizer(
vocab_file=os.path.join(model_dir, "sp.model"),
eos_token=tokenizer_config.get("eos_token"),
pad_token=tokenizer_config.get("pad_token"),
cls_token=tokenizer_config.get("cls_token"),
mask_token=tokenizer_config.get("mask_token"),
unk_token=tokenizer_config.get("unk_token"),
)
image_processor = M2EncoderImageProcessor.from_pretrained(model_dir)
text_inputs = tokenizer(
["杰尼龟", "妙蛙种子", "小火龙", "皮卡丘"],
padding="max_length",
truncation=True,
max_length=52,
return_special_tokens_mask=True,
return_tensors="np",
)
image_inputs = image_processor(Image.open("pokemon.jpeg").convert("RGB"), return_tensors="np")
text_session = ort.InferenceSession(
os.path.join(model_dir, "onnx", "text_encoder.onnx"),
providers=["CPUExecutionProvider"],
)
image_session = ort.InferenceSession(
os.path.join(model_dir, "onnx", "image_encoder.onnx"),
providers=["CPUExecutionProvider"],
)
text_embeds = text_session.run(
None,
{
"input_ids": text_inputs["input_ids"],
"attention_mask": text_inputs["attention_mask"],
},
)[0]
image_embeds = image_session.run(
None,
{"pixel_values": image_inputs["pixel_values"]},
)[0]
Runnable script:
python examples/run_onnx_inference.py --image pokemon.jpeg --text 杰尼龟 妙蛙种子 小火龙 皮卡丘
This repo includes a handler.py for Hugging Face Inference Endpoints custom deployments.
Example request body:
{
"inputs": {
"text": ["杰尼龟", "妙蛙种子", "小火龙", "皮卡丘"],
"image": "https://clip-cn-beijing.oss-cn-beijing.aliyuncs.com/pokemon.jpeg"
},
"parameters": {
"return_probs": true,
"return_logits": false
}
}
Example response fields:
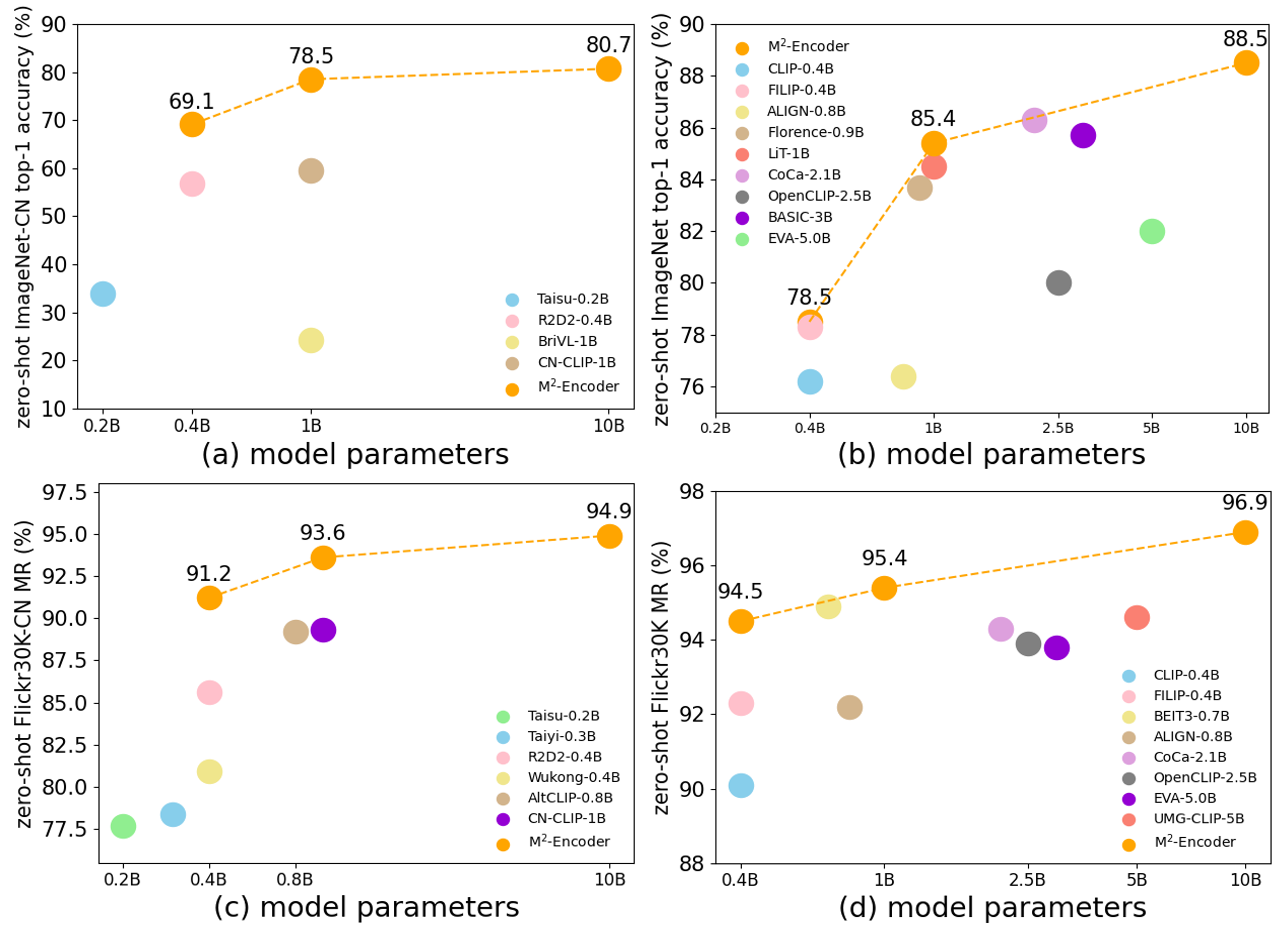
text_embeddingimage_embeddingscoresprobslogits_per_image when return_logits=trueAccording to the official project README and paper, the M2-Encoder series is trained on the bilingual BM-6B corpus and evaluated on:
The official project reports that the M2-Encoder family sets strong bilingual retrieval and zero-shot classification results, and that the 10B variant reaches 88.5 top-1 on ImageNet and 80.7 top-1 on ImageNet-CN in the zero-shot setting. See the paper for exact cross-variant comparisons.
The structured model-index metadata in this card is taken from the official paper tables for this released variant. On the Hugging Face page, those results should surface in the evaluation panel once the metadata is parsed.
transformers implementation merged upstream.trust_remote_code=True is required for AutoModel and AutoProcessor.@misc{guo2024m2encoder,
title={M2-Encoder: Advancing Bilingual Image-Text Understanding by Large-scale Efficient Pretraining},
author={Qingpei Guo and Furong Xu and Hanxiao Zhang and Wang Ren and Ziping Ma and Lin Ju and Jian Wang and Jingdong Chen and Ming Yang},
year={2024},
url={https://arxiv.org/abs/2401.15896}
}